# Mysql
| 🐉 必须了解的 MySQL 三大日志 | 🐉 走索引的情况和不走索引的情况 |
|---|---|
| explain 分析 sql 执行性能 | MySQL 中,写 SQL 的好习惯 |
| 8 种最坑 SQL 语法 | mysql 监控 |
| mysql 中的语法 | mysql 中的函数 |
| 恢复误删误修改数据 | mysql 命令手册 |
| 实用 sql 技巧 | 跨库分页/ 分表分页/ 跨库分页 |
| 10 大经典错误 | 设计规约 |
SQL 执行的顺序
from > on > join > where > group by > having > select > distinct > order by > limit
# 问题集锦
# Operand should contain 1 column(s)
操作数只能含 1 个
这个语句的出现多是因为将 select 的结果集用()包住了
# Every derived table must have its own alias
可能是括号(多了,没有成对出现
# Illegal mix of collations (utf8mb4_unicode_ci,IMPLICIT) and (utf8mb4_0900_ai_ci,IMPLICIT) for operat
建库的时候就要选择好 chartset 和 COLLATE 值;
连表查询时,排序编码规则不一致
-- 查看表创建时的编码规则
show create table table_name;
2
修改成一致
alter table ff_wb.wb_items default character set utf8mb4 collate utf8mb4_0900_ai_ci;
字段修改
alter table ff_wb.wb_items modify COMPANY_ID varchar(64) character set utf8mb4 COLLATE utf8mb4_0900_ai_ci;
# 启动服务
执行以下命令出错:
net start mysql
报服务名无效
原因是:因为 net start +服务名,启动的是 win 下注册的服务。此时,系统中并没有注册 mysql 到服务中。即当前路径下没有 mysql 服务。
解决方法一步骤如下:
1.来到 mysql 的安装目录下的 bin 路径
2.执行mysqld --install
成功:出现 Service successfully install 代表你已经安装成功,
不成功:出现Install/Remove of the Service Denied!
如果出现以上文字的时候,你需要用管理员的身份运行DOS窗口,这样就可以成功了
3.执行 net start mysql 出现
解决方法二步骤如下: 1.打开服务的界面,找到 mysql 相关的服务
2.确认其名称,再执行net start +服务名即可
# 通过 navicate 修改 mysql 密码
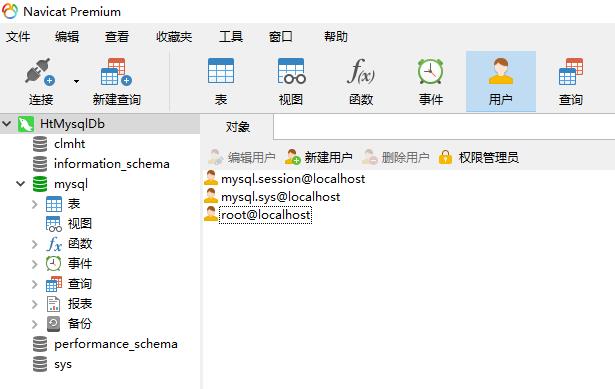
选中图中需要修改的用户的密码,修改好后直接保存即可。
# 双引号引发的坑
update tablename set source_name = "bj1062-北京市朝阳区常营北辰福第"
where source_name = "-北京市朝阳区常营北辰福第"
2
乍一看没啥问题。同样的 sql 需要执行大概 100 多条
执行完一条后没啥问题,符合预期结果。然后开发执行了剩下的 SQL,都是和上面的 SQL 一样,将地址进行更新。执行完成后,开发懵逼了,发现 source_name 都变成了 0,开发赶紧给我打电话说:
我赶紧登上服务器,查看了这段时间的 binlog,发现了大量的update tablename set source_name=0的语句,利用 binlog2sql 进行了解析,
在写 SQL 的过程中,一定要小心引号的位置是否正确,有时候引号位置错误,SQL 依然是正常的,但是却会导致执行结果全部错误。在执行前必须在测试环境执行测试,结合 IDE 的语法高亮发现相应的问题。(人为失误)
# You can't specify target table '表名' for update in FROM clause
TIP
在 MySQL 中,写 SQL 语句的时候 ,可能会遇到 You can't specify target table '表名' for update in FROM clause 这样的错误,它的意思是说,不能先 select 出同一表中的某些值,再 update 这个表(在同一语句中),即不能依据某字段值做判断再来更新某字段的值。
将 SELECT 出的结果再通过中间表 SELECT 一遍,这样就规避了错误。
WARNING
MSSQL 和 Oracle 不会出现此问题
# 排序中的 null
# mysql 排序含 null 时
mysql 中认为 null 在排序时为最小值。
- 降序时,会把 null 排在最后面;
- 升序时,会把 null 排在最前面
所以针对实际项目需求,可能需要对升序的进行处理,把 null 排在最后面,解决方法如下:
SELECT * FROM `ts_wb_signin` ORDER BY UPDATE_USER IS NULL, UPDATE_USER ASC
加上UPDATE_USER IS NULL这一句
或者
SELECT * FROM `ts_wb_signin` ORDER BY ISNULL(UPDATE_USER) ASC;
或者,排序字段前加上负号“-”,同时把“ASC”改为“DESC”,
SELECT * FROM `ts_wb_signin` ORDER BY -UPDATE_USER desc;
以上都可实现升序排序时,null 值排到最后面。
ORDER BY IFNULL(
myDate, '9999-12-31') ASC
# oracle 排序韩 null 时
oracle 中认为 null 在排序时为最大值
- 降序时,会把 null 排在最前面;
- 升序时,会把 null 排在最后面;
oracle 提供了函数 NULLS LAST或者NULLS FIRST
ORDER BY GATHERTIME DESC NULLS LAST
# 分页
利用关键字
limit,计算开始序号(startNum)及查询的总条数(totalNum)
select * from my_table limit 12,5;
# 数字字符串排序问题
# 简单实现+0(首推)
ORDER BY 'COLUMN'+0;
/**
* 根据项目ID及序号获取详细内容
* @param itemId 项目ID
* @param num 序号
* @return List<TsWbInsStd>
*/
@Select("SELECT T.TWO_CODE,T.TWO_NAME,T.THREE_CODE,T.THREE_NAME,T.TYPE,T.ID " +
"FROM TS_WB_INS_STD T " +
"WHERE T.ITEMS_ID=#{itemId} " +
"AND T.FLAG='2' AND T.ONE_CODE=#{num} " +
"ORDER BY T.TWO_CODE+0 ASC,T.THREE_CODE ASC")
List<TsWbInsStd> maintainStdContent(@Param("itemId") String itemId,@Param("num") String num);
}
2
3
4
5
6
7
8
9
10
11
12
13
# 获取最大日期记录
SELECT * FROM ODT_SIGNIN t
WHERE t.CREATE_TIME=(SELECT MAX(ocpp.CREATE_TIME) FROM odt_signin ocpp WHERE ocpp.CHECK_TASK_ID=t.CHECK_TASK_ID)
2
# CAST
ORDER BY CAST('123' AS SIGNED);
# CONVERT
ORDER BY CONVERT('123',SIGNED);
# 设置字段值为 null
update tablename set col=null where
# sql 语句执行顺序
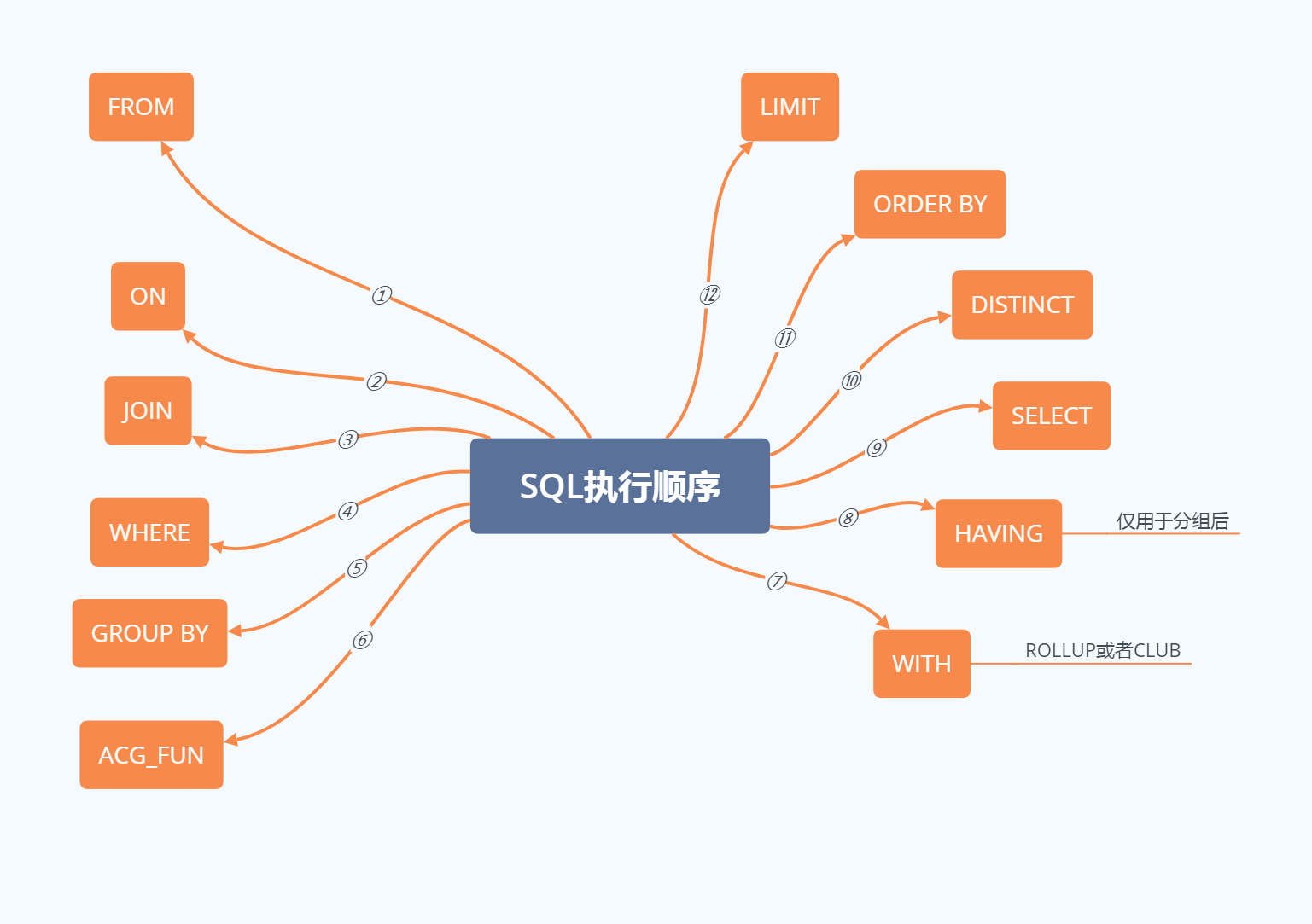
从这个顺序中我们可以发现,所有的查询语句都是从 FROM 开始执行的。在实际执行过程中,每个步骤都会为下一个步骤生成一个虚拟表,这个虚拟表将作为下一个执行步骤的输入。 接下来,
# FROM 执行笛卡尔积
FROM 才是 SQL 语句执行的第一步,并非 SELECT 。对 FROM 子句中的前两个表执行笛卡尔积(交叉联接),生成虚拟表VT1,获取不同数据源的数据集。
FROM 子句执行顺序为从后往前、从右到左,FROM 子句中写在最后的表(基础表 driving table)将被最先处理,即最后的表为驱动表,当 FROM 子句中包含多个表的情况下,我们需要选择数据最少的表作为基础表。
# ON 应用 ON 过滤器
对虚拟表 VT1 应用 ON 筛选器,ON 中的逻辑表达式将应用到虚拟表 VT1 中的各个行,筛选出满足 ON 逻辑表达式的行,生成虚拟表 VT2 。
# JOIN 添加外部行
如果指定了 OUTER JOIN 保留表中未找到匹配的行将作为外部行添加到虚拟表 VT2,生成虚拟表 VT3。保留表如下:
- LEFT OUTER JOIN 把左表记为保留表
- RIGHT OUTER JOIN 把右表记为保留表
- FULL OUTER JOIN 把左右表都作为保留表
在虚拟表 VT2 表的基础上添加保留表中被过滤条件过滤掉的数据,非保留表中的数据被赋予 NULL 值,最后生成虚拟表 VT3。
如果 FROM 子句包含两个以上的表,则对上一个联接生成的结果表和下一个表重复执行步骤 1~3,直到处理完所有的表为止。
4 WHERE 应用 WEHRE 过滤器 对虚拟表 VT3 应用 WHERE 筛选器。根据指定的条件对数据进行筛选,并把满足的数据插入虚拟表 VT4。
由于数据还没有分组,因此现在还不能在 WHERE 过滤器中使用聚合函数对分组统计的过滤。 同时,由于还没有进行列的选取操作,因此在 SELECT 中使用列的别名也是不被允许的。 5 GROUP BY 分组 按 GROUP BY 子句中的列/列表将虚拟表 VT4 中的行唯一的值组合成为一组,生成虚拟表 VT5。如果应用了 GROUP BY,那么后面的所有步骤都只能得到的虚拟表 VT5 的列或者是聚合函数(count、sum、avg 等)。原因在于最终的结果集中只为每个组包含一行。
同时,从这一步开始,后面的语句中都可以使用 SELECT 中的别名。
6 AGG_FUNC 计算聚合函数 计算 max 等聚合函数。SQL Aggregate 函数计算从列中取得的值,返回一个单一的值。常用的 Aggregate 函数包涵以下几种:
AVG:返回平均值 COUNT:返回行数 FIRST:返回第一个记录的值 LAST:返回最后一个记录的值 MAX: 返回最大值 MIN:返回最小值 SUM: 返回总和 7 WITH 应用 ROLLUP 或 CUBE 对虚拟表 VT5 应用 ROLLUP 或 CUBE 选项,生成虚拟表 VT6。
CUBE 和 ROLLUP 区别如下:
CUBE 生成的结果数据集显示了所选列中值的所有组合的聚合。 ROLLUP 生成的结果数据集显示了所选列中值的某一层次结构的聚合。 8 HAVING 应用 HAVING 过滤器 对虚拟表 VT6 应用 HAVING 筛选器。根据指定的条件对数据进行筛选,并把满足的数据插入虚拟表 VT7。
HAVING 语句在 SQL 中的主要作用与 WHERE 语句作用是相同的,但是 HAVING 是过滤聚合值,在 SQL 中增加 HAVING 子句原因就是,WHERE 关键字无法与聚合函数一起使用,HAVING 子句主要和 GROUP BY 子句配合使用。
9 SELECT 选出指定列 将虚拟表 VT7 中的在 SELECT 中出现的列筛选出来,并对字段进行处理,计算 SELECT 子句中的表达式,产生虚拟表 VT8。
10 DISTINCT 行去重 将重复的行从虚拟表 VT8 中移除,产生虚拟表 VT9。DISTINCT 用来删除重复行,只保留唯一的。
11 ORDER BY 排列 将虚拟表 VT9 中的行按 ORDER BY 子句中的列/列表排序,生成游标 VC10 ,注意不是虚拟表。因此使用 ORDER BY 子句查询不能应用于表达式。同时,ORDER BY 子句的执行顺序为从左到右排序,是非常消耗资源的。
12 LIMIT/OFFSET 指定返回行 从 VC10 的开始处选择指定数量行,生成虚拟表 VT11,并返回调用者。
# 实例
select 班级,avg(数学成绩) as 数学平均成绩
from 学生信息表
where 数学成绩 is not null
group by 班级
having 数学平均成绩>80
order by 数学平均成绩 desc
limit 3
2
3
4
5
6
7
首先,我们先看下如上 SQL 的执行顺序,如下:
- 首先执行 FROM 子句, 从学生成绩表中组装数据源的数据。
- 执行 WHERE 子句, 筛选学生成绩表中所有学生的数学成绩不为 NULL 的数据 。
- 执行 GROUP BY 子句, 把学生成绩表按 "班级" 字段进行分组。
- 计算 avg 聚合函数, 按找每个班级分组求出 数学平均成绩。
- 执行 HAVING 子句, 筛选出班级 数学平均成绩大于 75 分的。
- 执行 SELECT 语句,返回数据,但别着急,还需要执行后面几个步骤。
- 执行 ORDER BY 子句, 把最后的结果按 "数学平均成绩" 进行排序。
- 执行 LIMIT ,限制仅返回 3 条数据。结合 ORDER BY 子句,即返回所有班级中数学平均成绩的前三的班级及其数学平均成绩。
如果修改上述语句如下:
select 班级,avg(数学成绩) as 数学平均成绩
from 学生信息表
where 数学成绩 is not null and 数学平均成绩>80
group by 班级
order by 数学平均成绩 desc
limit 3
2
3
4
5
6
会报错,此时 GROUP BY 语句还未执行,因此此时聚合值 avg(数学成绩) 还是未知的,因此会报错。
# 字段类型问题
# json 类型问题及相关 json 解析查询
老老实实用 text 结构的类型吧,mysql 在存储 json 时按照 key 的字段长度做了排序,以便获得更好的存储性能,目前不支持顺序 json,所以还是自己第三方工具序列化下吧
mysql 本身是关系型数据库,对文档类型的数据还是用 nosql 吧比如 MongoDB
JSON_EXTRACT(原字段,'$.json字段名')
如果 key 对应的 value 不存在,则返回 null
- 一、解析 json 字符串
select t.ID,t.DATA,json_extract(t.DATA,'$."134"') as bat from dev_data_last t where t.ID='003a04da24e8988c16dda4240c9999e4';
-- 数字类型的key必须加上双引号
select t.WARN_VALUES,json_extract(t.WARN_VALUES,'$.heart') as heart from dev_device t where t.ID='433268d4a7b7f88c971dd36b9070af35';
-- 字母类型的key则可有可无双引号
2
3
4
003a04da24e8988c16dda4240c9999e4,"{""130"": 0, ""134"": -50.0, ""141"": -50.0, ""142"": -50.0, ""143"": 26.9, ""148"": 0.0, ""149"": 0.0, ""150"": 0.0, ""151"": 0.0, ""152"": 0.0, ""153"": 0.0}",-50.0
"{""heart"": ""10.0"", ""sleep"": ""2.0"", ""upAlmVal"": ""450.0"", ""lowAlmVal"": ""50.0""}","""10.0"""
2
3
可以看出带引号的 json value 解析出来后引号较多。可采取如下手段屏蔽不必要的引号
- replace
select t.WARN_VALUES,replace(json_extract(t.WARN_VALUES,'$."heart"'),'"','') as heart from dev_device t where t.ID='433268d4a7b7f88c971dd36b9070af35';
- json_unquote
select t.WARN_VALUES, json_unquote(json_extract(t.WARN_VALUES,'$."heart"')) as heart from dev_device t where t.ID='433268d4a7b7f88c971dd36b9070af35';
TIP
如果是 json 数组,则$[*].url 或者 $[0].url,获取全部的 url 或者某个下标的 url
# msi 安装步骤
https://dev.mysql.com/downloads/下载安装包

# zip 安装步骤
https://dev.mysql.com/downloads/下载后之后将文件解压到你想放置的 mysql 文件位置
- 第一步:设置环境变量
将你解压后放置的文件里边的 bin 目录加入到 path 中。例如:D:\Sql Server\mysql-8.0.12-winx64\bin
- 第二步:配置初始化 my.ini
在 D:\Sql Server\mysql-8.0.12-winx64 中创建添加 my.ini
[mysqld]
# 设置3306端口
port=3306
# 设置mysql的安装目录
basedir=D:\\Sql Server\\mysql-8.0.12-winx64
# 切记此处一定要用双斜杠\\,单斜杠我这里会出错。
# 设置mysql数据库的数据的存放目录
datadir=D:\\Sql Server\\mysql-8.0.12-winx64\\Data # 此处同上
# 允许最大连接数
max_connections=200
# 允许连接失败的次数。这是为了防止有人从该主机试图攻击数据库系统
max_connect_errors=10
# 服务端使用的字符集默认为UTF8
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
# 默认使用“mysql_native_password”插件认证
default_authentication_plugin=mysql_native_password
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
[client]
# 设置mysql客户端连接服务端时默认使用的端口
port=3306
default-character-set=utf8
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
第三步:以管理员身份运行 cmd 命令,并将路径换到 mysql 的 bin 目录下
3.1 初始化数据库,运行命令:
mysqld --initialize --console
其中这句要粘贴到记事本上,以防忘记,上边是默认密码
A temporary password is generated for root@localhost: rI5rvf5x5G,E
3.2 安装服务,允许命令:
mysqld --install [服务名]
其中服务名可以不写,默认是 mysql
至此 mysql 就安装完毕了
- 运行 mysql
net start mysql
- 停止 mysql
net stop mysql
- 想要更改密码
运行 cmd,在 bin 目录下运行命令:
mysql -u root -p 输入上边记录的密码,在进行修改密码操作
2018-08-22T01:00:18.469000Z 5 [Note] [MY-0104
s generated for root@localhost: %jq9awYjh!O&
2
- 本机 mysql-root 密码:root/123456
# 大厂必须遵守的 MySql 开发军规
# mysql 中 emoji 表情转换入库
public class EmojiUtil {
/**
* @Description emoji表情转换入库
* @param str 待转换字符串
* @return 转换后字符串
* @throws UnsupportedEncodingException
*/
public static String emojiToUtf(String str)
throws UnsupportedEncodingException {
String patternString = "([\\x{10000}-\\x{10ffff}\ud800-\udfff])";
Pattern pattern = Pattern.compile(patternString);
Matcher matcher = pattern.matcher(str);
StringBuffer con = new StringBuffer();
while (matcher.find()) {
try {
matcher.appendReplacement(con,"[[" + URLEncoder.encode(matcher.group(1),"UTF-8") + "]]");
} catch (UnsupportedEncodingException e) {
throw e;
}
}
matcher.appendTail(con);
return con.toString();
}
/**
* @Description 还原emoji表情的字符串
* @param str 转换后的字符串
* @return 转换前的字符串
* @throws UnsupportedEncodingException
*/
public static String utfToEmoji(String str)
throws UnsupportedEncodingException {
String patternString = "\\[\\[(.*?)\\]\\]";
Pattern pattern = Pattern.compile(patternString);
Matcher matcher = pattern.matcher(str);
StringBuffer con = new StringBuffer();
while (matcher.find()) {
try {
matcher.appendReplacement(con,
URLDecoder.decode(matcher.group(1), "UTF-8"));
} catch (UnsupportedEncodingException e) {
throw e;
}
}
matcher.appendTail(con);
return con.toString();
}
// 第一个方法是将字段中的emoji表情转换入库。
String content=“”;
try {
content = EmojiUtil.emojiToUtf(content);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
// 第二个方法是讲 转化后的字符还原为 emoji表情:
String content = comm.getStr("content");
if (StringUtils.isNotBlank(content)) {
try {
content = EmojiUtil.utfToEmoji(content);
comm.set("content", content);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
也可参考github
# 命令
# 表结构及数据备份
# 1、复制表结构及数据到新表(不包含主键、索引、分区等)
CREATE TABLE 新表 SELECT * FROM 旧表
-- 或
CREATE TABLE 新表 AS SELECT * FROM 旧表
2
3
这种方法将旧表基本结构和数据复制到新表。
不过这种方法的一个最不好的地方就是新表中没有了旧表的主键、索引、Extra(auto_increment,字符集编码及排序)、注释、分区等属性 以及触发器、外键等。
# 2、只复制表结构到新表
CREATE TABLE 新表 SELECT * FROM 旧表 WHERE 1=2 (只是第一种方式去除掉数据)
-- 或者下面方式
CREATE TABLE 新表 LIKE 旧表
2
3
4
这种方式的复制可以复制旧表的主键、索引、Extra(auto_increment,字符集编码及排序)、注释、分区等属性。但是不包含触发器、外键等,执行时间会慢一些
# 3、复制旧表的数据到新表
INSERT INTO 新表 SELECT * FROM 旧表
INSERT INTO 新表(字段1,字段2,.......) SELECT 字段1,字段2,...... FROM 旧表
2
3
上面两条语句的前提是新表已经存在
# 4、复制表结构及数据到新表(包含主键、索引、分区等)
结合上述第2、3点,即:
-- 先
CREATE TABLE 新表 LIKE 旧表
--然后
INSERT INTO 新表 SELECT * FROM 旧表
2
3
4
5
# 5、可以将表1结构复制到表2(mysql不支持)
SELECT * INTO 表2 FROM 表1 WHERE 1=2
# 6、可以将表1内容全部复制到表2(mysql不支持)
SELECT * INTO 表2 FROM 表1
# 7、 show create table 旧表
这样会将旧表的创建命令列出。我们只需要将该命令拷贝出来,更改table的名字,就可以建立一个完全一样的表
# 导库和备份相关
- 导入数据库
mysql > mysql -uroot -p --show-warnings --default-character-set=utf8 $DBNAME < $SOURCESQL
mysql > source $SOURCESQL
2
- 备份 MySQL 数据库的命令
mysqldump -hhostname -uusername -ppassword databasename > backupfile.sql
- 备份 MySQL 数据库为带删除表的格式 备份 MySQL 数据库为带删除表的格式,能够让该备份覆盖已有数据库而不需要手动删除原有数据库。
mysqldump -–add-drop-table -uusername -ppassword databasename > backupfile.sql
- 直接将 MySQL 数据库压缩备份
mysqldump -hhostname -uusername -ppassword databasename | gzip > backupfile.sql.gz
- 备份 MySQL 数据库某个(些)表
mysqldump -hhostname -uusername -ppassword databasename specific_table1 specific_table2 > backupfile.sql
- 同时备份多个 MySQL 数据库
mysqldump -hhostname -uusername -ppassword –databases databasename1 databasename2 databasename3 > multibackupfile.sql
- 仅仅备份数据库结构
mysqldump –no-data –databases databasename1 databasename2 databasename3 > structurebackupfile.sql
- 备份服务器上所有数据库
mysqldump –all-databases > allbackupfile.sql
- 还原 MySQL 数据库的命令
mysql -hhostname -uusername -ppassword databasename < backupfile.sql
- 还原压缩的 MySQL 数据库
gunzip < backupfile.sql.gz | mysql -uusername -ppassword databasename
- 将数据库转移到新服务器
mysqldump -uusername -ppassword databasename | mysql –host=*.*.*.* -C databasename
# 查看 binlog 日志
mysqlbinlog -v --base-output=DECODE-ROWS --start-position= --stop-position= --start-datetime="2015-01-01 01:01:01" --stop-datetime="" -d | grep -i ""
# 查看版本信息
mysql --version
# COLLATE 属性
COLLATE
如 VARCHAR,CHAR,TEXT 类型的列,都需要有一个 COLLATE 类型来告知 mysql 如何对该列进行排序和比较。
简而言之,COLLATE
- 会影响到 ORDER BY 语句的顺序
- 会影响到 WHERE 条件中大于小于号筛选出来的结果
- 会影响DISTINCT、GROUP BY、HAVING语句的查询结果。
另外,mysql 建索引的时候,如果索引列是字符类型,也会影响索引创建,只不过这种影响我们感知不到。总之,凡是涉及到字符类型比较或排序的地方,都会和 COLLATE 有关。
每种 CHARSET 都指定一种 COLLATE 为默认值
Latin1编码的默认 COLLATE 为latin1_swedish_ciGBK编码的默认 COLLATE 为gbk_chinese_ciutf8mb4编码的默认值为utf8mb4_general_ci
_ci: Case Insensitive 的缩写,即大小写无关
_cs后缀的 COLLATE,则是 Case Sensitive,即大小写敏感的。
国内比较常用的是utf8mb4_general_ci(默认)、utf8mb4_unicode_ci、utf8mb4_bin 这三个
# mysql中创建数据库并创建用户
语法过时:MySQL 8.0+已禁用
GRANT ... IDENTIFIED BY联合语法
mysql -h 127.0.0.1 -u root -P 13306 -p
create database if not exists team_nav default charset utf8mb4 collate utf8mb4_general_ci;
CREATE USER 'teamNav'@'%' IDENTIFIED WITH mysql_native_password BY 'teamNav';
grant all privileges on team_nav.* to 'teamNav'@'%';
flush privileges;
2
3
4
5
6
7
8
9
# 验证权限及删除权限
SHOW GRANTS FOR 'teamNav'@'%';
-- 撤销全局权限
REVOKE ALL PRIVILEGES, GRANT OPTION
FROM 'teamNav'@'%';
-- 撤销数据库级权限
REVOKE ALL PRIVILEGES ON `teamnav`.*
FROM 'teamNav'@'%';
-- 撤销角色关联(MySQL 8.0+专属)
REVOKE ALL ROLES FROM 'user'@'host';
2
3
4
5
6
7
8
9
10
11
12