# cmd
# 登录用户
# 切换用户的命令
su username
# 从普通用户切换到root用户
sudo su
# 退出当前用户回到原先用户
exit
# 或者
logout
# 或者ctrl+d
2
3
4
5
6
7
8
9
10
切换用户时,如果想在切换之后使用新用户的工作环境,可以在su和username之间加上-
su - dmdba
# 查看空间情况
# disk free
df -h
# 查看分区情况
lsblk
# 查看各个文件夹的占用空间信息
du -sh *
2
3
4
5
6
7
8
# 查看服务器配置
# 查看cpu核数,返回数字,如:4
cat /proc/cpuinfo | grep processor | wc -l
# 查看cpu型号,如:Intel(R) Xeon(R) Gold 6132 CPU @ 2.60GHz
cat /proc/cpuinfo | grep 'model name' | uniq
# 查看主板信息
dmidecode | grep -A16 'System Information$'
# 查看内存信息
dmidecode | grep -A16 'Memory Device$'
# 或者
dmidecode -t memory
# 查看内存插槽数
dmidecode | grep -P -A5 "Memory\s+Device" | grep Size | grep -V Range
# 查看已经安装的内存
grep MemTotal /proc/meminfo
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 查看服务器架构信息
uname -a
# 操作系统系统版本
lsb_release -a
- 内存
free
# 文件校验hashmd5
sha1sum file.tar.gz
md5sum file.tar.gz
sha256 file.tar.gz
sha224 file.tar.gz
sha512 file.tar.gz
2
3
4
5
6
# 重命名
# 使用mv
# -i:存在一个二次确认的动作,以免误操作
mv -i text1.txt text2.txt
2
# 使用cp
# 使用rename
需要安装,可以批量重命名
rename 老文件 新文件 需要重命名的老文件
rename text1.txt text2.txt text1.txt
# 所有的txt文件都重命名为log文件
rename .txt .log *.txt
# 所有文件名中含有TestFile的log文件都重命名为tt log文件
rename TestFile tt TestFile*.log
2
3
4
5
6
7
# 端口使用情况
# 指定端口
netstat –tunlp | grep 8080
# 或者
lsof –i:8080
# 所有端口
netstat –ntlp
# 查看某进程端口占用
ps –ef | grep tomcat
2
3
4
5
6
7
8
9
10
# 查看所有安装的服务信息
# 列出所有已经安装的服务
systemctl list-unit-files --type=service
# 列出所有active(运行或者退出)的服务
systemctl list-units --type=service --state=active
# 列出所有正在运行的服务
systemctl list-units --type=service --state=running
# 列出所有正在运行或者failed的服务
systemctl list-units --type=service --state=running,failed
# 列出所有已经安装的服务的状态,需要密码
service --status-all
# 列出所有已安装的服务及其启动级别
chkconfig --list
# 列出所有正在运行的服务
ps -ef | grep service
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# Linux firewall防火墙
# 查看防火墙状态
systemctl status firewalld
# 开启防火墙
systemctl start firewalld
# 或者
service firewalld start
# 开机启动
systemctl enable firewalld
# 关闭防火墙
systemctl stop firewalld
# 若遇到无法开启
systemctl unmask firewalld.service
systemctl start firewalld.service
# 查看对外开放的端口状态
netstat -tunlp | grep 18090
# 查看当前系统所有开放的端口
firewall-cmd --list-ports
# 返回yes表示开放,no表示未开放
firewall-cmd --query-port=18090/tcp
# 开放端口
firewall-cmd --add-port=18091/tcp --permanent
firewall-cmd --reload
firewall-cmd --query-port=18091/tcp
# 批量开放端口
firewall-cmd --add-port=100-500/tcp --permanent
# 移除端口
firewall-cmd --permanent --remove-port=18091/tcp
# 批量移除开放的端口
firewall-cmd --permanent --remove-port=100-500/tcp
# 限制IP地址访问
firewall-cmd --permanent --add-rich-rule="rule family="ipv4" source address="128.64.162.1" port protocol="tcp" port="18090" reject"
firewall-cmd --reload
# 查看已经设置的规则
firewall-cmd --list-rich-rules
firewall-cmd --zone=public --list-rich-rules
# 解除ip地址限制
firewall-cmd --permanent --add-rich-rule="rule family="ipv4" source address="128.64.162.1" port protocol="tcp" port="18090" accept"
# 如果解除未生效,可尝试直接编辑文件
vi /etc/firewalld/zones/public.xml
# 限制ip段,24代表255.255.255.0,共包含256个IP,解除限制同单个ip
firewall-cmd --permanent --add-rich-rule="rule family="ipv4" source address="10.0.0.0/24" port protocol="tcp" port="18090" reject"
firewall-cmd --reload
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| 标识 | IP总数 | 子网掩码 | C段个数 |
|---|---|---|---|
/30 | 4 | 255.255.255.252 | 1/64 |
/29 | 8 | 255.255.255.248 | 1/32 |
/28 | 16 | 255.255.255.240 | 1/16 |
/27 | 32 | 255.255.255.224 | 1/8 |
/26 | 64 | 255.255.255.192 | 1/4 |
/24 | 256 | 255.255.255.0 | 1 |
/23 | 512 | 255.255.254.0 | 2 |
/22 | 1024 | 255.255.252.0 | 4 |
/21 | 2048 | 255.255.248.0 | 8 |
/20 | 4096 | 255.255.240.0 | 16 |
/19 | 8192 | 255.255.224.0 | 32 |
/18 | 16384 | 255.255.192.0 | 64 |
/17 | 32768 | 255.255.128.0 | 128 |
/16 | 65536 | 255.255.0.0 | 256 |
# base64加解密
-- base64编码
base64 file
printf 'atfs123456' | base64
printf 'atfs123456' | base64
printf -n 'atfs123456' | base64
-- base64解码
base64 -d file
printf "QXRmc185Nzgy" | base64 -d
# 解密后:Atfs_9782
printf -n "YXRmczEyMw==" | base64 -d
2
3
4
5
6
7
8
9
10
11
echo 和 printf 都是用于在 shell 脚本中输出文本的命令,但它们有一些区别:
格式化输出:
echo通常用于简单的文本输出,不支持格式化字符串。printf允许你使用格式化字符串,类似于C语言的printf函数,可以更灵活地控制输出的格式,包括指定宽度、精度、对齐等。
转义字符的处理:
echo会解释并处理转义字符,例如\n表示换行。printf不会自动解释转义字符,除非使用格式化控制符,如%s、%n等。
跨平台兼容性:
echo是一个 shell 内建命令,因此具有较好的跨平台兼容性,但在一些特殊情况下可能有不同的行为。printf也是 shell 内建命令,但一些系统可能提供了独立的 printf 可执行文件,其行为可能略有不同。
示例:
# 使用 echo 输出文本
echo "Hello, World!"
# 使用 printf 输出格式化文本
printf "Hello, %s!\n" "World"
2
3
4
5
总的来说,对于简单的文本输出,echo 足够用了。如果你需要更复杂的格式化输出,特别是在脚本中处理变量和格式时,printf 可能更适合。
# case_in
基本语法
case 变量名 in #对变量进行判断
变量值1) #当变量名的值是变量值1时,依次输出命令1,命令2
命令1
命令2
命令n;;
变量值2)
命令1
命令2
命令n;;
变量值3)
命令1
....
命令n;;
esac #结束标记
2
3
4
5
6
7
8
9
10
11
12
13
14
- 变量名,可以加双引号,也可以不加
- 每个case子句的
条件测试部分都以右括号")"结束 - case子句
以";;"结束 - case语句
以esac结尾
#!/bin/bash
echo '输入用户名:(例如老王)'
read user
echo
case $user in
zhangsan)
echo -e "姓名:张三\n外号:法外狂徒\n年龄:十七\n擅长:无恶不作,无中生有,无语无语,无可救药\n职业:刑法演示家";;
laowang)
echo -e "姓名:老王,\n外号:寡妇终结者,中国好邻居\n擅长:辣手摧黄花做绿帽使者\n职业:人体构造学工程师";;
*)
echo "暂无收录"
esac
2
3
4
5
6
7
8
9
10
11
12
# cat命令
# -A会展示所有特殊字符
cat file.txt -A
# 将file1的内容覆写到file2中
cat file1.txt > file2.txt
2
3
4
5
# chgrp
change group,变更文件或目录的所属用户组,允许普通用户改变文件所属用户组,前提是用户为该组一员
# 文件所属组变更为htg
chgrp -v htg file1.txt
# 参考file2.txt的用户组变更file1.txt的用户组信息
chgrp --refrence=file2.txt file1.txt
2
3
4
5
# chmod
change mode,控制用户对文件的权限
- Linux/Unix 文件调用分为三级
- 文件所有者(Owner)【rwx】
- 用户组(Group)【rwx】
- 其他用户(Other Users)【rwx】
# u-所有者,g-用户组,o-其他用户 +表示增加权限, r-读,w-写,x-执行
# 为所有用户增加读权限,
chmod ugo+r file1.zip
# 或者
chmod a+r file1.zip
chmod ug+w,o-w file1.zip file2.txt
# 设置当前目录下所有文件设为任何人可读
chmod -R a+r *
# 二进制法,所有用户增加读写执行的权限
chmod 777 file1.txt
# 文件具有root权限
chmod 4755 file1.txt
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# chown
change owner用于设置文件所有者和管理的用户组,需要root用户才有此命令的执行权限,非root用户可以使用chgrp
# 把文件所有者设置为root
chown root /var/run/tj-atf.pid
# 将文件的所有者设置为ht,用户组设置为htg
chown ht:htg file1.txt
# 将当前目录下的所有文件的所有者设为ht,用户组设为htg
chown -R ht:htg *
# 将目录的关联用户组设为htg,但是不改变所有者
chown :htg /var/run
2
3
4
5
6
7
8
9
10
11
# cp
copy file
# 源文件:要复制的文件或者目录的路径
# 目标文件:标识复制后的文件或者目录的路径
cp [选项] 源文件 目标文件
2
3
# cp选项说明
-a:通常复制目录时使用,它保留链接、文件属性,并复制目录下的所有内容,作用等同于dpR-d:复制时保留链接(相当于windows系统中的快捷方式-r或者--recursive:用于复制目录及其所有的子目录和文件-i或者--interactive:复制前进行提示,如果目标文件已存在则询问是否覆盖-u或者--update:仅复制源文件中更新时间较新的文件-p或者--preserve:保留源文件的权限、所有者和时间戳信息-f或者--force:强制复制-l:不复制文件,仅生成链接文件
# curl
# date
# 格式化日期显示
date [选项]… [+格式]
date "+%Y-%m-%d"
date +"%Y-%m-%d"
# 2023-09-12
date +"%Y-%m-%d %H:%M:%S"
# 2023-09-12 19:12:45
2
3
4
5
6
-(连字符)不填充该区域_(下划线)以空格填充0用0填充^,如果可能,使用大写字母#,如果可能,使用小写字母
| 符号 | 含义 |
|---|---|
%a | 当前locale的星期名的缩写(如:日,代表星期日) |
%A | 当前locale的星期名的全称(如:星期日) |
%b | 当前locale的月名的缩写(如:一,代表一月) |
%B | 当前locale的月名的全称(如:一月) |
%c | 当前locale的日期和时间(如:2023年9月13日 星期三 16:33:34) |
%C | 世纪(如:20),通常是省略当前年份后两位数字 |
%I大写的字母i | 小时(00-12)(如:当前是16:42,则结果为:04) |
%k | 小时(0-23)(如:当前是09:42,则结果为:9) |
%l小写的字母L | 小时(1-12)(如:当前是16:42,则结果为:4) |
%n | 换行 |
%N | 纳秒 |
%p | 当前locale的上午或者下午,未知时输出空 |
%y | 年份的后两位 |
%Y | 年份 |
%m | 月份(01-12) |
%d | 按月计的日期(如:04) |
%H | 小时(00-23)(如:22) |
%M | 分钟(00-59) |
%S | 秒(00-59) |
%D | 等于%m%d%y(如:09/13/23) |
%F | 等于%Y-%m-%d(如:2023-09-13) |
%R | 等于%H:%M |
%T | 等于%H:%M:%S |
%s | 自utc时间1970-01-01 00:00:00以来所经过的秒数 |
%t | 输出制表符tab |
# 获取前后日期
date -d [选项]
# 当前日期20230912,day、days、month、months,year、years、hour……
date -d "3 day" +"%Y%m%d"
# 20230915
# 加上ago表示前n天
date -d "3 day ago" +"%Y%m%d"
# 20230909
# 获取指定日期的日期差,20231108
date -d "20231111 -3 days" +"%Y%m%d"
# 一些快捷方式
date -d "yesterday"
date -d "tomorrow"
date -d "last month"
date -d "next month"
date -d "last year"
date -d "next year"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# diff
在Linux中,你可以使用diff命令来比较两个文件的内容差异。以下是一个简单的示例:
diff file1.txt file2.txt
这将输出两个文件之间的差异。如果文件内容相同,则没有输出。如果有差异,diff会显示差异的行,并标记添加或删除的内容。
如果你想生成一个可读性更好的差异报告,你可以使用-u选项:
diff -u file1.txt file2.txt
此外,你还可以将diff的输出重定向到文件,以便稍后查看:
diff -u file1.txt file2.txt > diff_output.txt
这将把差异输出保存到名为 diff_output.txt 的文件中。
# find
find [path] -name filename
find [path] -name '*.js'
2
# grep
获取指定字符串前后N行信息:
# -i:不区分大小写
# -n:n需替换为具体数字,表示显示目标字符串上下n行信息
grep -10 -i 'A0991AC01' atflog/mSrv1_message.log
# -c:展示目标字符串所在行数
grep -c -i 'reacT' file.txt
2
3
4
5
6
# gzip
gzip [选项] 压缩(解压缩)的文档名
标准的 GNU/UNIX 压缩工具, 取代了比较差的 compress 命令.
相应的解压命令是 gunzip, 与gzip -d是等价的.
| 描述 | 各选项的含义: |
|---|---|
-c | 将输出写到标准输出上,并保留原有文档。 |
-d | 将压缩文档解压。 |
-l | 对每个压缩文档,显示下列字段: 压缩文档的大小 未压缩文档的大小 压缩比 未压缩文档的名字 |
--r | 递归式地查找指定目录并压缩其中的任何文档或是解压缩。 |
--t | 测试,检查压缩文档是否完整。 |
--v | 对每一个压缩和解压的文档,显示文档名和压缩比。 |
--num | 用指定的数字 num 调整压缩的速度-1 或 --fast 表示最快压缩方法(低压缩比),-9 或 --best 表示最慢压缩方法(高压缩比)系统 缺省值为 6 。 |
# 递归地压缩目录 test
$gzip -r test
这样,所有 test 下面的文件都变成了 *.gz ,目录依然存在只是目录里面的文件相应变成了 *.gz .这就是压缩,和打包不同。因为是对目录操作,所以需要加上-r选项,这样也可以对子目录进行递归了。
# 递归地解压目录 test
$gzip -d -r test
# 或
$gunzip -r test
2
3
这样, test 里面的所有 *.gz 文件还原成原来的文件。
# 将当前目录下的所有文件压缩
$gzip *
这样所有非目录的文件都会被压缩,注意这里原来的文件都被替换成为压缩之后的文件了。
# 将当前目录下的所有压缩文件解压
$gzip -d *
# 或
$gunzip *
2
3
这样会将目录下面所有压缩的文件解压。
# 解压当前目录下的所有压缩文件,并显示详细的解压信息
$gzip -d -v *
# 或
$gzip -dv *
# 或
$gunzip -v *
2
3
4
5
这样 -v 选项显示了更多的信息。同理 gzip 的 -v 选项会显示压缩的时候的更为详细的信息。
# 详细显示当前目录下面的压缩文件的信息
$gzip -l *
输入之后,输出如下:
gzip: dirnew is a directory -- ignored
gzip: dirold is a directory -- ignored
compressed uncompressed ratio uncompressed_name
178 215 31.6% testRename.c
2699 6521 59.1% testRename
2877 6736 57.7% (totals)
2
3
4
5
6
这里只是显示压缩文档的信息,并不显示。
# 详细显示某个压缩文件的信息
$gzip -l testRename.c.gz
输入之后,输出如下:
compressed uncompressed ratio uncompressed_name
178 215 31.6% testRename.c
2
# 压缩一个 tar 备份文档
$gzip dirnew.tar
执行之后,会将 dirnew.tar 变成 dirnew.tar.gz ,压缩了。
# kill
发送信号到进程
kill -9 PID
kill -s 信号名称
kill -n 信号名称对应的数字
# 列出信号名称
kill -l
2
3
4
5
6
# java命令
# ln软链接的使用
软连接是linux中一个常用命令,它的功能是为某一个文件在另外一个位置建立一个同不的链接。
具体用法是:ln -s 源文件 目标文件。
当 我们需要在不同的目录,用到相同的文件时,我们不需要在每一个需要的目录下都放一个必须相同的文件,我们只要在其它的 目录下用ln命令链接(link)就可以,不必重复的占用磁盘空间。
例如:
ln -s /usr/local/mysql/bin/mysql /usr/bin
这样我们就对/usr/bin目录下的mysql命令创建了软连接
# 硬连接
硬连接指通过索引节点来进行连接。在Linux的文件系统中,保存在磁盘分区中的文件不管是什么类型都给它分配一个编号,称为索引节点号(Inode Index)。在Linux中,多个文件名指向同一索引节点是存在的。一般这种连接就是硬连接。硬连接的作用是允许一个文件拥有多个有效路径名,这样用户就可以建立硬连接到重要文件,以防止“误删”的功能。
其原因如上所述,因为对应该目录的索引节点有一个以上的连接。只删除一个连接并不影响索引节点本身和其它的连接,只有当最后一个连接被删除后,文件的数据块及目录的连接才会被释放。也就是说,文件真正删除的条件是与之相关的所有硬连接文件均被删除。
# 软连接
另外一种连接称之为符号连接(Symbolic Link),也叫软连接。软链接文件有类似于Windows的快捷方式。
它实际上是一个特殊的文件。在符号连接中,文件实际上是一个文本文件,其中包含的有另一文件的位置信息。
# 创建软链接
ln -s [源文件或目录] [目标文件或目录]
例:
当前路径创建test 引向/var/www/test 文件夹
ln –s /var/www/test test
创建/var/test 引向/var/www/test 文件夹
ln –s /var/www/test /var/test
# 删除软链接
和删除普通的文件是一样的,删除都是使用rm来进行操作
删除test
rm –rf test
修改软链接
ln –snf [新的源文件或目录] [目标文件或目录]
这将会修改原有的链接地址为新的地址
例如:
创建一个软链接
ln –s /var/www/test /var/test
修改指向的新路径
ln –snf /var/www/test1 /var/test
| 常用参数 | 含义 |
|---|---|
-f | 链结时先将与 dist 同档名的档案删除 |
-d | 允许系统管理者硬链结自己的目录 |
-i | 在删除与 dist 同档名的档案时先进行询问 |
-n | 在进行软连结时,将 dist 视为一般的档案 |
-s | 进行软链结(symbolic link) |
-v | 在连结之前显示其档名 |
-b | 将在链结时会被覆写或删除的档案进行备份 |
-S SUFFIX | 将备份的档案都加上 SUFFIX 的字尾 |
-V METHOD | 指定备份的方式 |
--help | 显示辅助说明 |
--version | 显示版本 |
# ls查看文件夹文件个数
ll并非一个存在的命令,只是ls -l --color=auto的别名
-h:以人类更容易读懂的单位显示-f:不排序-d:显示自身目录属性-k:以字节为单位显示-m:以逗号为间隔输出-q:以问号代替所有无法显示的字符-Q:文件名加上引号-r:反向排序文件-s:显示文件名时加上大小信息-S:按大小排序-t:根据时间排序-u:根据访问时间排序
# 查看目录下多少个文件(含目录和文件)
ls | wc -w
# 仅统计当前文件夹下文件个数
ls -l | grep "^-" | wc -l
# 仅统计当前文件夹下目录个数
ls -l | grep "^d" | wc -l
# 含子目录
ls -lR | grep "^-" | wc -l
# 查看目录下多杀字节数
ls | wc -c
2
3
4
5
6
7
8
9
10
11
12
13
14
# mkdir
make directory
# -p确保目录名称存在,不存在就创建
mkdir [-p] dirname
2
-p参数在建立多级目录时较有用
# 在目录htr下新建一个ht的目录,若htr目录本就不存在,此时又没加-p参数,则会报错;
# 而加了-p参数之后,如果htr目录不存在,就创建一个htr目录
mkdir -p ~/htr/ht
2
3
# ps
process status,显示当前进程,类似windows的任务管理器
# ps -ef
System V风格
| UID | PID | PPID | C | STIME | TTY | TIME | CMD |
|---|---|---|---|---|---|---|---|
用户ID,但是输出的是用户名 | 进程ID | 父进程ID | 进程占CPU的百分比 | 进程启用到现在的时间 | 该进程在哪个终端上运行 若与终端无关则显示 ?若为 pts/0则表示由网络连接主机进程 | 该进程实际使用CPU运行的时间 | 命令的名称和参数 |
dmdba 3602057 1 0 17:41 pts/0 00:00:00 sh imp_batch.sh 20230811 ATFS
# ps -aux
BSD风格
会截断命令,当结合grep时会影响结果
| USER | PID | %CPU | %MEM | VSZ | RSS | TTY | STAT | START | TIME | COMMAND |
|---|---|---|---|---|---|---|---|---|---|---|
| 进程拥有者 | 进程ID | / | / | 占用虚拟内存大小 | 占用的内存大小 | / | 进程状态 | 进程开始时间 | 执行时间 | 执行的命令 |
| atfs | 17153 | 0.5 | 9.1 | 3722192 | 734520 | ? | S1 | 9月09 | 80:43 | /home/ap/atfs/java/bin/java -server -Djava.io.tmpdir=/home…… |
- 进程状态
| 值 | 描述 |
|---|---|
| D | 无法中断的休眠状态(通常IO进程) |
| R | 正在执行中 |
| S | 静止状态 |
| T | 暂停执行 |
| Z | 不存在但是暂时无法消除 |
| W | 没有足够的内存可分配 |
| < | 高优先的进程 |
| N | 低优先的进程 |
| L | 有内存可分配并锁在内存中 |
# ps -A
列出所有的进程
# ps -a
显示所有终端机下执行的程序
# rm、rmdir
rm file.txt
# 删除目录及目录下所有内容
rm -rf ht/
# 如果目录为空,则删除该目录
rmdir ht/
2
3
4
5
6
7
# tar
tar没有解压并新建目录的指令
# 解压tar
tar -xvf file.tar
# 解压tar.gz
tar –zxvf file.tar.gz
# 解压tar.bz2
tar –xjvf file.tar.bz2
# 解压tar.gz到指定目录
tar –zxvf file.tar.gz -C ~/
# 压缩
tar -zcvf file.tar.gz ~/app
# 查看文件
tar -tf file.tar.gz
# 删除tar包里的内容
tar --delete -vf file.tar.gz file2012.txt file2012.txt
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
tar参数信息
-c:新建打包文件,同-v一起使用,查看打包文件名-v:压缩或解压过程中,显示过程-f:要操作的文件名-r:表示增加文件,把要增加的文件追加在压缩文件的末尾-t:表示查看文件,查看文件中的内容-x:解压文件-z:通过gzip方式压缩或者解压,最后以.tar.gz为后缀-j:通过bzip2方式压缩或者解压,最后以.tar.br2为后缀-u:更新压缩包内容-p:保留绝对路径,即含有根目录信息-P:保留权限和属性
# touch
创建一个不含任何内容的空文件
touch ht.txt
# top
# vi&vim
vi 是linux中最基本的文本编辑器,了解它后,可在linux中畅行无阻
vi命令的三种状态:
- 1、命令模式(command mode);
- 控制屏幕光标的移动,字符、字或者行的删除,移动复制某区段以及进入其他2种模式
- 2、插入模式(insert mode);
- 命令模式下,输入
a,A,i,I,o,O中任何一个字符,即可进入插入模式 - 此模式下才可输入文字,按
esc可回到命令模式
- 命令模式下,输入
- 3、底行模式(last line mode)
- 命令模式下,输入英文冒号(
:)即可切换到底行模式 - 保存文件或者退出vi,也可设置编辑器环境,如查找字符串、列出行号等
- 底行模式下命令以
回车结束,退出或者返回命令模式,或者双击esc返回命令模式
- 命令模式下,输入英文冒号(
a:在当前光标下一位开始编辑
A:在当前光标所在行的行尾开始编辑
i:在当前光标开始编辑
I:在当前光标所在行行首开始编辑
o:在当前光标的下一行开始编辑
O:在当前光标的上一行开始编辑
2
3
4
5
6
# 默认进入命令模式
vi tj-atf-info.log
2
// 命令模式下常用命令
dd // 删除(剪切)光标所在行整行
ndd // 删除光标所在行起向下n行(如:5dd,删除5行)
yy // 复制光标所在行
nyy // 复制n行
p // 粘贴
x // 向后删除光标所在字符
X // 向前删除光标所在字符
gg // 把光标跳转到本文件的第一行
G // 把光标跳转到本文件的最后一行
u // 撤销,返回上一步
r // 替换当前光标所在位置
2
3
4
5
6
7
8
9
10
11
12
// 底行模式下常用命令
:set nu //显示行号
:set nonu // 取消显示行号
:q //只退出不保存
:wq // 保存退出
:q! // 强制退出
:wq! // 强制保存退出
:%s/old/new // 将old替换成new
:/string // 从文本开头处开始查找字符串,然后按小写n可定位到下一个匹配的字符串,大写的N定位到上一个匹配的字符串
:?string // 从文本结尾处开始查找字符串
:n // 定位到第n行
2
3
4
5
6
7
8
9
10
11
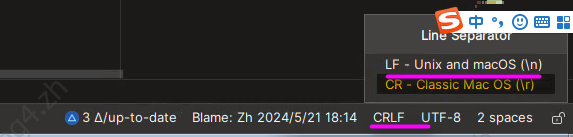
# 删除windows换行符^M
# 安装dos2unix工具
dos2unix file.sh
vi -b file.sh
# 命令模式下输入:%s/^M//g或者g/\^M/s/\^M//;注意^M的输入方式为:ctrl+v+m
vim file.sh
# 命令模式下输入:setff=unix
2
3
4
5
6
7
8
最根本的解决还是从源头,如果使用的是IDEA,则可以调整换行符为unix的
# |:管道命令
通常情况下,我们在终端只能执行一条命令,然后按下回车执行,那么如何执行多条命令呢?
顺序执行多条命令:command1;command2;command3;
简单的顺序指令可以通过;来实现。
有条件的执行多条命令:which command1 && command2 || command3
&&: 如果前一条命令执行成功则执行下一条命令,和JavaScript中用法一致||:与&&命令相反,执行不成功时执行下一个。$?: 存储上一次命令的返回结果
# 如果存在git命令,执行git --help命令
$ which git>/dev/null && git --help
$ echo $?
2
3
而管道命令则可以衔接各种命令的输出输入,使得连锁操作变得简单。
管道是一种通信机制,通常用于进程间的通信(也可通过socket进行网络通信),它表现出来的形式将前面每一个进程的输出(stdout)直接作为下一个进程的输入(stdin)
$ 指令1 | 指令2 | …
- 管道命令的注意事项:
- 只能处理前一条指令的正确输出,不能处理错误输出;
- 后一条指令,必须能够接收标准输入流命令才能执行。
# zip
| 参数 | 意义 |
|---|---|
| -A | 调 整可执行的自动解压缩文件。 |
| -b<工作目录> | 指 定暂时存放文件的目录。 |
| -c | 替 每个被压缩的文件加上注释。 |
| -d | 从 压缩文件内删除指定的文件。 |
| -D | 压 缩文件内不建立目录名称。 |
| -f | 此 参数的效果和指定"-u"参 数类似,但不仅更新既有文件,如果某些文件原本不存在于压缩文件内,使用本参数会一并将其加入压缩文件中。 |
| -F | 尝 试修复已损坏的压缩文件。 |
| -g | 将 文件压缩后附加在既有的压缩文件之后,而非另行建立新的压缩文件。 |
| -h | 在 线帮助。 |
| -i<范本样式> | 只 压缩符合条件的文件。 |
| -j | 只 保存文件名称及其内容,而不存放任何目录名称。 |
| -J | 删 除压缩文件前面不必要的数据。 |
| -k | 使 用MS-DOS兼容格 式的文件名称。 |
| -l | 压 缩文件时,把LF字符 置换成LF+CR字 符。 |
| -ll | 压 缩文件时,把LF+CR字 符置换成LF字符。 |
| -L | 显 示版权信息。 |
| -m | 将 文件压缩并加入压缩文件后,删除原始文件,即把文件移到压缩文件中。 |
| -n<字尾字符串> | 不 压缩具有特定字尾字符串的文件。 |
| -o | 以 压缩文件内拥有最新更改时间的文件为准,将压缩文件的更改时间设成和该文件相同。 |
| -q | 不显 示指令执行过程。 |
| -r | 递 归处理,将指定目录下的所有文件和子目录一并处理。 |
| -S | 包 含系统和隐藏文件。 |
| -t<日期时间> | 把 压缩文件的日期设成指定的日期。 |
| -T | 检 查备份文件内的每个文件是否正确无误。 |
| -u | 更 换较新的文件到压缩文件内。 |
| -v | 显 示指令执行过程或显示版本信息。 |
| -V | 保 存VMS操作系统的文 件属性。 |
| -w | 在 文件名称里假如版本编号,本参数仅在VMS操 作系统下有效。 |
| -x<范本样式> | 压 缩时排除符合条件的文件。 |
| -X | 不 保存额外的文件属性。 |
| -y | 直 接保存符号连接,而非该连接所指向的文件,本参数仅在UNIX之 类的系统下有效。 |
| -z | 替 压缩文件加上注释。 |
| -$ | 保 存第一个被压缩文件所在磁盘的卷册名称。 |
| -<压缩效率> | 压 缩效率是一个介于1-9的 数值。 |
# unzip
unzip [options] file.zip
# 将文件解压至指定目录
unzip -d ~/tmp file.zip
2
3
4
| 选项 | 含义 |
|---|---|
-d | 解压至指定目录 |
-n | 解压时不覆盖已存在的文件 |
-o | 解压时覆盖已存在的文件,并无需用户确认 |
-v | 查看压缩文件信息,但不做解压操作 |
-t | 测试压缩文件是否损坏,但并不做解压操作 |
-x | 解压文件,但不包含文件列表指定的文件 |
| 参数 | 意义 |
|---|---|
| -c | 将 解压缩的结果显示到屏幕上,并对字符做适当的转换。 |
| -f | 更 新现有的文件。 |
| -l | 显 示压缩文件内所包含的文件。 |
| -p | 与-c参数类似,会将解压缩的结果显示到屏幕上,但不会执行任 何的转换。 |
| -t | 检 查压缩文件是否正确。,但不解压。 |
| -u | 与-f参数类似,但是除了更新现有的文件外,也会将压缩文件中 的其他文件解压缩到目录中。 |
| -v | 执 行是时显示详细的信息。或查看压缩文件目录,但不解压。 |
| -z | 仅 显示压缩文件的备注文字。 |
| -a | 对 文本文件进行必要的字符转换。 |
| -b | 不 要对文本文件进行字符转换。 |
| -C | 压 缩文件中的文件名称区分大小写。 |
| -j | 不 处理压缩文件中原有的目录路径。 |
| -L | 将 压缩文件中的全部文件名改为小写。 |
| -M | 将 输出结果送到more程 序处理。 |
| -n | 解 压缩时不要覆盖原有的文件。 |
| -o | 不 必先询问用户,unzip执 行后覆盖原有文件。 |
| -P<密码> | 使 用zip的密码选项。 |
| -q | 执 行时不显示任何信息。 |
| -s | 将 文件名中的空白字符转换为底线字符。 |
| -V | 保 留VMS的文件版本信 息。 |
| -X | 解 压缩时同时回存文件原来的UID/GID |
| [.zip文件] | 指定.zip压缩文件。 |
| [文件] | 指定 要处理.zip压缩文 件中的哪些文件。 |
| -d<目录> | 指 定文件解压缩后所要存储的目录。 |
| -x<文件> | 指 定不要处理.zip压 缩文件中的哪些文件。 |
| -Z | unzip -Z等 于执行zipinfo指 令 |