# 容器
| 🐉 LinkedList |
|---|
# ArrayList 重拳出击,把 LinkedList 干翻在地
时间复杂度
在计算机科学中,算法的时间复杂度(Time complexity)是一个函数,它定性描述该算法的运行时间。
这是一个代表算法输入值的字符串的长度的函数。时间复杂度常用大 O 符号表述,不包括这个函数的低阶项和首项系数。
使用这种方式时,时间复杂度可被称为是渐近的,亦即考察输入值大小趋近无穷时的情况。例如,如果一个算法对于任何大小为 n (必须比 n0 大)的输入,它至多需要 5n3 + 3n 的时间运行完毕,那么它的渐近时间复杂度是 O(n3)。
# add(E e)
方法会默认将元素添加到数组末尾,但需要考虑到数组扩容的情况,如果不需要扩容,时间复杂度为 O(1)。
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
size = s + 1;
}
2
3
4
5
6
7
8
9
10
11
12
如果需要扩容的话,并且不是第一次(oldCapacity > 0)扩容的时候,内部执行的 Arrays.copyOf() 方法是耗时的关键,需要把原有数组中的元素复制到扩容后的新数组当中。
private Object[] grow(int minCapacity) {
int oldCapacity = elementData.length;
if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, /* minimum growth */
oldCapacity >> 1 /* preferred growth */);
return elementData = Arrays.copyOf(elementData, newCapacity);
} else {
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
}
}
2
3
4
5
6
7
8
9
10
11
# add(int index, E element)
方法将新的元素插入到指定的位置,考虑到需要复制底层数组(根据之前的判断,扩容的话,数组可能要复制一次),根据最坏的打算(不管需要不需要扩容,System.arraycopy() 肯定要执行),所以时间复杂度为 O(n)
public void add(int index, E element) {
rangeCheckForAdd(index);
modCount++;
final int s;
Object[] elementData;
if ((s = size) == (elementData = this.elementData).length)
elementData = grow();
System.arraycopy(elementData, index,
elementData, index + 1,
s - index);
elementData[index] = element;
size = s + 1;
}
2
3
4
5
6
7
8
9
10
11
12
13
来执行以下代码,把沉默王八插入到下标为 2 的位置上。
ArrayList<String> list = new ArrayList<>();
list.add("沉默王二");
list.add("沉默王三");
list.add("沉默王四");
list.add("沉默王五");
list.add("沉默王六");
list.add("沉默王七");
list.add(2, "沉默王八");
2
3
4
5
6
7
8
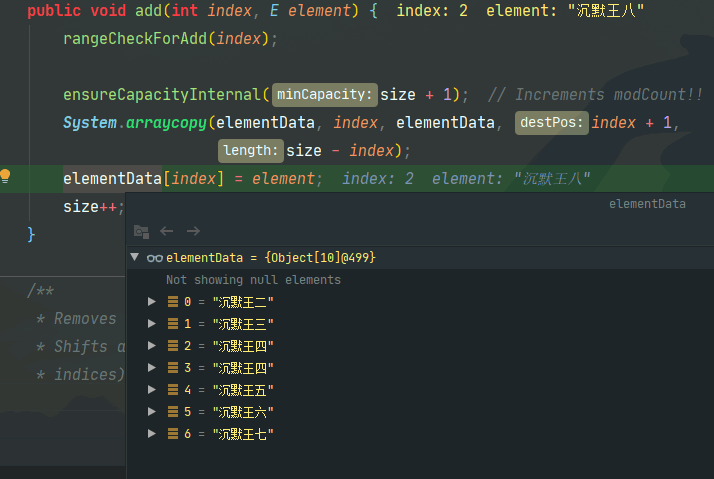
System.arraycopy() 执行完成后,下标为 2 的元素为沉默王四,这一点需要注意。也就是说,在数组中插入元素的时候,会把插入位置以后的元素依次往后复制,所以下标为 2 和下标为 3 的元素都为沉默王四。
之后再通过 elementData[index] = element 将下标为 2 的元素赋值为沉默王八;随后执行 size = s + 1,数组的长度变为 7
# remove(int index)
方法将指定位置上的元素删除,考虑到需要复制底层数组,所以时间复杂度为 O(n)
public E remove(int index) {
Objects.checkIndex(index, size);
final Object[] es = elementData;
@SuppressWarnings("unchecked") E oldValue = (E) es[index];
fastRemove(es, index);
return oldValue;
}
private void fastRemove(Object[] es, int i) {
modCount++;
final int newSize;
if ((newSize = size - 1) > i)
System.arraycopy(es, i + 1, es, i, newSize - i);
es[size = newSize] = null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# get(int index)-LinkedList
方法的时间复杂度为 O(n),因为需要循环遍历整个链表。
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
LinkedList.Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
LinkedList.Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
LinkedList.Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
下标小于链表长度的一半时,从前往后遍历;否则从后往前遍历,这样从理论上说,就节省了一半的时间。
TIP
如果下标为 0 或者 list.size() - 1 的话,时间复杂度为 O(1)。这种情况下,可以使用 getFirst() 和 getLast() 方法。
public E getFirst() {
final LinkedList.Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
public E getLast() {
final LinkedList.Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
2
3
4
5
6
7
8
9
10
11
12
13
first 和 last 在链表中是直接存储的,所以时间复杂度为 O(1)。
# add(E e)-LinkedList
默认将元素添加到链表末尾,所以时间复杂度为 O(1)
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final LinkedList.Node<E> l = last;
final LinkedList.Node<E> newNode = new LinkedList.Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# add(int index, E element)-LinkedList
方法将新的元素插入到指定的位置,需要先通过遍历查找这个元素,然后再进行插入,所以时间复杂度为 O(n)。
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
2
3
4
5
6
7
8
TIP
如果下标为 0 或者 list.size() - 1 的话,时间复杂度为 O(1)。这种情况下,可以使用 addFirst() 和 addLast() 方法。
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final LinkedList.Node<E> f = first;
final LinkedList.Node<E> newNode = new LinkedList.Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
- linkFirst() 只需要对 first 进行更新即可。
- linkLast() 只需要对 last 进行更新即可。
LinkedList 插入元素的时间复杂度近似 O(1),其实是有问题的,因为 add(int index, E element) 方法在插入元素的时候会调用 node(index) 查找元素,该方法之前我们之间已经确认过了,时间复杂度为 O(n),即便随后调用 linkBefore() 方法进行插入的时间复杂度为 O(1),总体上的时间复杂度仍然为 O(n) 才对。
void linkBefore(E e, LinkedList.Node<E> succ) {
// assert succ != null;
final LinkedList.Node<E> pred = succ.prev;
final LinkedList.Node<E> newNode = new LinkedList.Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
2
3
4
5
6
7
8
9
10
11
12
# remove(int index)-LinkedList
方法将指定位置上的元素删除,考虑到需要调用 node(index) 方法查找元素,所以时间复杂度为 O(n)。
# A-L总结
- 需要注意的是,如果列表很大很大,ArrayList 和 LinkedList 在内存的使用上也有所不同。LinkedList 的每个元素都有更多开销,因为要存储上一个和下一个元素的地址。ArrayList 没有这样的开销。
- 查询的时候,ArrayList 比 LinkedList 快,这是毋庸置疑的;插入和删除的时候,LinkedList 因为要遍历列表,所以并不比 ArrayList 更快。反而 ArrayList 更轻量级,不需要在每个元素上维护上一个和下一个元素的地址。
- 如果 ArrayList 在增删改的时候涉及到大量的数组复制,效率就另当别论了,因为这个过程相当的耗时。
# List中获取最大值
List<Double> currencyList = new ArrayList<>();
currencyList.add(1.2);
currencyList.add(2.5);
currencyList.add(3.6);
System.out.println(Collections.max(currencyList));
3.6
List<String> currencyList = new ArrayList<>();
currencyList.add("ghrte");
currencyList.add("ythty");
currencyList.add("rte");
System.out.println(Collections.max(currencyList));
2
3
4
5
6
7
8
9
10
11
12
# List中最大值遇到java8
System.out.println(persons.stream()
.filter(obj -> obj.getAge() != null)
.max(Comparator.comparingInt(PersonModel::getAge))
.orElse(null));
System.out.println(persons.stream()
.filter(obj -> obj.getAge() != null)
.sorted(Comparator.comparingInt(PersonModel::getAge).reversed())
.findFirst()
.orElse(null));
2
3
4
5
6
7
8
9
10
# 数组遍历转ArrayList
- for循环数组
- 工具类
Collections.addAll(list2,232,3434,1312);
addAll()方法的实现就是用的上面遍历的方式。
- java8
List<Integer> list2 = Arrays.stream(intArray).boxed().collect(Collectors.toList());
- 两个集合类结合
List<String> listInteger = new ArrayList<>(Arrays.asList("dsds","sdfasfd","oio"));
# Arrays.asList
使用
Arrays.asList()的原因无非是想将数组或一些元素转为集合,而你得到的集合并不一定是你想要的那个集合。
而一开始asList的设计时用于打印数组而设计的,但jdk1.5开始,有了另一个比较更方便的打印函数Arrays.toString(),于是打印不再使用asList(),而asList()恰巧可用于将数组转为集合。
# asList错误用法
- 错误一:将
基本类型数组作为asList的参数
int[] intArray = {1,2,3};
List listsInt = Arrays.asList(intArray);
System.out.println(listsInt.size());
//输出结果为:1;
2
3
4
由于Arrays.ArrayList参数为可变长泛型,而基本类型是无法泛型化的,
所以它把int[] arr数组当成了一个泛型对象,所以集合中最终只有一个元素arr。
- 错误二:将数组作为asList参数后,修改数组或List
String[] strArray = {"我","知道","陈莉敏","最好看"};
List<String> listsStr = Arrays.asList(strArray);
strArray[1]="必须知道";
listsStr.set(3,"妥妥的最好看");
System.out.println(Arrays.toString(strArray));
// 输出结果:[我, 必须知道, 陈莉敏, 妥妥的最好看]
System.out.println(listsStr.toString());
// 输出结果:[我, 必须知道, 陈莉敏, 妥妥的最好看]
2
3
4
5
6
7
8
由于asList产生的集合元素是直接引用作为参数的数组,所以当外部数组或集合改变时,
数组和集合会同步变化,这在平时我们编码时可能产生莫名的问题。
- 错误三:数组转换为集合后,进行增删元素
listsStr.add("who");
listsStr.remove(1);
System.out.println(listsStr.toString());
2
3
直接异常,没有重写add和remove方法
由于asList产生的集合并没有重写add,remove等方法,所以它会调用父类AbstractList的方法,
而父类的方法中抛出的却是异常信息。
# asList不同之处
Arrays.ArrayList 是工具类 Arrays 的一个内部静态类,它没有完全实现List的方法,而 ArrayList直接实现了List 接口,实现了List所有方法。
- 1.长度不同 和 实现的方法不同
Arrays.ArrayList是一个定长集合,因为它没有重写add,remove方法,所以一旦初始化元素后,集合的size就是不可变的。
- 2.参数赋值方式不同
Arrays.ArrayList将外部数组的引用直接通过“=”赋予内部的泛型数组,所以本质指向同一个数组。
# asList正确姿势
- 如果使用Spring
int[] intArray = {2,3,4};
//此处返回的还是Arrays.asList
List list1 = CollectionUtils.arrayToList(intArray);
// list1.add(6);
System.out.println(list1);
2
3
4
5
- 如果使用Java 8
List<Integer> list2 = Arrays.stream(intArray).boxed().collect(Collectors.toList());
// for (Integer i:list2){
// if (i==2){
// list2.remove(i);
// }
// }
list2.add(7);
2
3
4
5
6
7
注释掉的部分,会报错。
此时可以随意增减的。
# 14个Java并发容器
不考虑多线程并发的情况下,容器类一般使用ArrayList、HashMap等线程不安全的类,效率更高
- ConcurrentHashMap:并发版HashMap
- CopyOnWriteArrayList:并发版ArrayList
- CopyOnWriteArraySet:并发Set
- ConcurrentLinkedQueue:并发队列(基于链表)
- ConcurrentLinkedDeque:并发队列(基于双向链表)
- ConcurrentSkipListMap:基于跳表的并发Map
- ConcurrentSkipListSet:基于跳表的并发Set
- ArrayBlockingQueue:阻塞队列(基于数组)
- LinkedBlockingQueue:阻塞队列(基于链表)
- LinkedBlockingDeque:阻塞队列(基于双向链表)
- PriorityBlockingQueue:线程安全的优先队列
- SynchronousQueue:读写成对的队列
- LinkedTransferQueue:基于链表的数据交换队列
- DelayQueue:延时队列
# 删除操作
Collection.removeIf();
# sort排序
- 第一种:实现Comparator接口的类的对象作为sort的入参
public class HumanComparetor implements Comparator<Human> {
@Override
public int compare(Human h1, Human h2) {
if (h1.getAge() > h2.getAge()) {
return 1;
} else if (h1.getAge() == h2.getAge()) {
return 0;
} else {
return -1;
}
}
}
public static void main(String[] args) {
List<Human> humans = Human.getAInitHumanList();
Collections.sort(humans, new HumanComparetor());
System.out.println(humans);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
- 第二种:在方法的局部使用局部类,原理和第一种差不多
public static void main(String[] args) {
List<Human> humans = Human.getAInitHumanList();
//方法内-局部类
class HumanComparetor implements Comparator<Human> {
@Override
public int compare(Human h1, Human h2) {
return h1.getAge() - h2.getAge();
}
}
Collections.sort(humans, new HumanComparetor());
System.out.println(humans);
}
2
3
4
5
6
7
8
9
10
11
12
- 第三种:基于第二种方法,局部类改为匿名类
public static void main(String[] args) {
List<Human> humans = Human.getAInitHumanList();
//匿名类
Collections.sort(humans, new Comparator<Human>() {
@Override
public int compare(Human h1, Human h2) {
return h1.getAge() - h2.getAge();
}
});
System.out.println(humans);
}
2
3
4
5
6
7
8
9
10
11
- 第四种:使用lamdba表达式->这种形式
public static void main(String[] args) {
List<Human> humans = Human.getAInitHumanList();
//lamdba 表达式 ->
Collections.sort(humans, (Human h1, Human h2) -> h1.getAge() - h2.getAge());
System.out.println(humans);
}
2
3
4
5
6
- 第五种:借助Comparator和lamdba表达式多条件排序
public static void main(String[] args) {
List<Human> humans = Human.getAInitHumanList();
////lamdba 表达式 ::
Collections.sort(humans, Comparator.comparing(Human::getAge).thenComparing(Human::getName));
System.out.println(humans);
}
2
3
4
5
6
- 第六种:调用方式和第五种有区别,原理一样
public static void main(String[] args) {
List<Human> humans = Human.getAInitHumanList();
//直接用list.sort
humans.sort(Comparator.comparing(Human::getAge).thenComparing(Human::getName));
System.out.println(humans);
}
2
3
4
5
6
# 根据另一个List的顺序来进行排序
// 这效率很低
Collections.sort(listB, new Comparator<Item>() {
public int compare(Item left, Item right) {
return Integer.compare(listA.indexOf(left), listA.indexOf(right));
}
});
Collections.sort(listToSort, Comparator.comparing(item -> listWithOrder.indexOf(item)));
// OR
listToSort.sort(Comparator.comparingInt(listWithOrder::indexOf));
2
3
4
5
6
7
8
9
10
11
# 获取集合中重复元素列表
如果是对象的话,需要重写equals方法
@Override
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (obj instanceof PersonModel) {
PersonModel person = (PersonModel) obj;
if (StringUtils.equals(person.getSex(), this.sex)
&& StringUtils.equals(person.getLastName(), this.lastName)
&& person.getAge().equals(this.age)) {
return true;
}
}
return super.equals(obj);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
@Test
public void testMultiSet() {
List<PersonModel> persons = Lists.newArrayList();
persons.add(new PersonModel("male", 14, "ting"));
persons.add(new PersonModel("male", 14, "ting"));
persons.add(new PersonModel("male", 15, "ting"));
persons.add(new PersonModel("male", 16, "ting"));
persons.add(new PersonModel("male", 16, "ting"));
persons.add(new PersonModel("male", 20, "ting"));
persons.add(new PersonModel("male", 31, "ting"));
// System.out.println(persons.count(new PersonModel("male",16,"ting")));
// persons.indexOf(obj) != persons.lastIndexOf(obj)此条件是获取非重复的列表
List<PersonModel> personss = persons.stream()
.filter(obj -> persons.indexOf(obj) != persons.lastIndexOf(obj))
.collect(Collectors.toList());
personss.forEach(System.out::println);
// System.out.println(persons);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 对象根据某字段属性去重
public static <T> Predicate<T> distinctByKey(Function<? super T, Object> keyFunction) {
Map<Object, Boolean> map = new ConcurrentHashMap<>();
return t -> map.putIfAbsent(keyFunction.apply(t), Boolean.TRUE) == null;
}
public static <T> Predicate<T> distinctByKey(Function<? super T, Object> keyFunction) {
Map<Object, Boolean> map = new ConcurrentHashMap<>();
return t -> {
// 存在则返回value,不存在则返回null并插入Boolean.true
Boolean v = map.putIfAbsent(keyFunction.apply(t), Boolean.TRUE);
System.out.println(v);
return v == null;
};
}
/**
* 并集并根据名去重
*/
public static List<PersonModel> unionPersons(List<PersonModel> personModels1, List<PersonModel> personModels2) {
return Stream.concat(personModels1.stream(), personModels2.stream())
.filter(distinctByKey(PersonModel::getLastName))
.collect(Collectors.toList());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 获取两个List的交集、并集、差集、去重并集
List<String> list1 = new ArrayList<String>();
list1.add("1");
list1.add("2");
list1.add("3");
list1.add("5");
list1.add("6");
List<String> list2 = new ArrayList<String>();
list2.add("2");
list2.add("3");
list2.add("7");
list2.add("8");
// 交集
List<String> intersection = list1.stream().filter(item -> list2.contains(item)).collect(toList());
System.out.println("---交集 intersection---");
intersection.parallelStream().forEach(System.out :: println);
// 差集 (list1 - list2)
List<String> reduce1 = list1.stream().filter(item -> !list2.contains(item)).collect(toList());
System.out.println("---差集 reduce1 (list1 - list2)---");
reduce1.parallelStream().forEach(System.out :: println);
// 差集 (list2 - list1)
List<String> reduce2 = list2.stream().filter(item -> !list1.contains(item)).collect(toList());
System.out.println("---差集 reduce2 (list2 - list1)---");
reduce2.parallelStream().forEach(System.out :: println);
// 并集
List<String> listAll = list1.parallelStream().collect(toList());
List<String> listAll2 = list2.parallelStream().collect(toList());
listAll.addAll(listAll2);
System.out.println("---并集 listAll---");
listAll.parallelStream().forEachOrdered(System.out :: println);
// 去重并集
List<String> listAllDistinct = listAll.stream().distinct().collect(toList());
System.out.println("---得到去重并集 listAllDistinct---");
listAllDistinct.parallelStream().forEachOrdered(System.out :: println);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
合并多个list并去重
public static List<String> findAreas(String street, String keyWord) {
List<CompanyVo> vos = CompanyUtil.getCompanyListByCompanyIds(findRightsByKeyWordAndStreet(street, keyWord));
if (CollectionUtils.isEmpty(vos)) {
return Lists.newArrayList();
}
return concat(vos.stream().map(CompanyVo::getId),
concat(vos.stream().map(CompanyVo::getProvince),
concat(vos.stream().map(CompanyVo::getCity),
concat(vos.stream().map(CompanyVo::getArea), vos.stream().map(CompanyVo::getStreet)
)
)
)
).distinct().collect(Collectors.toList());
}
2
3
4
5
6
7
8
9
10
11
12
13
14