# stream
惰性求值&强制求值
特别注意惰性求值、强制求值
Stream 是用函数式编程方式在集合类上进行复杂操作的工具。
Stream 里的一些方法却略有不同,它们虽是普通的Java 方法,但返回的Stream 对象却不是一个新集合,而是创建新集合的配方。
players.stream().filter(str->str.startsWith("N"))
players.stream().filter(str->{
System.out.println(str);
return str.startsWith("N");
});
// 没有输出。
Long count = players.stream().filter(str->{
System.out.println(str);
return str.startsWith("N");
}).count();
2
3
4
5
6
7
8
9
10
11
12
13
输出内容
Rafael Nadal
Novak Djokovic
Stanislas Wawrinka
David Ferrer
Roger Federer
Andy Murray
Tomas Berdych
Juan Martin Del Potro
Nhhhhhhhh
2
3
4
5
6
7
8
9
区分惰性求值与强制求值
判断一个操作是惰性求值还是及早(强制求值)求值很简单:只需看它的返回值。如果返回值是Stream,那么是惰性求值;
如果返回值是另一个值或为空,那么就是及早求值。
使用这些操作的理想方式就是形成一个惰性求值的链,最后用一个及早求值的操作返回想要的结果,这正是它的合理之处。
# Stream调试
工具IDEA,插件JAVA Stream Debugger
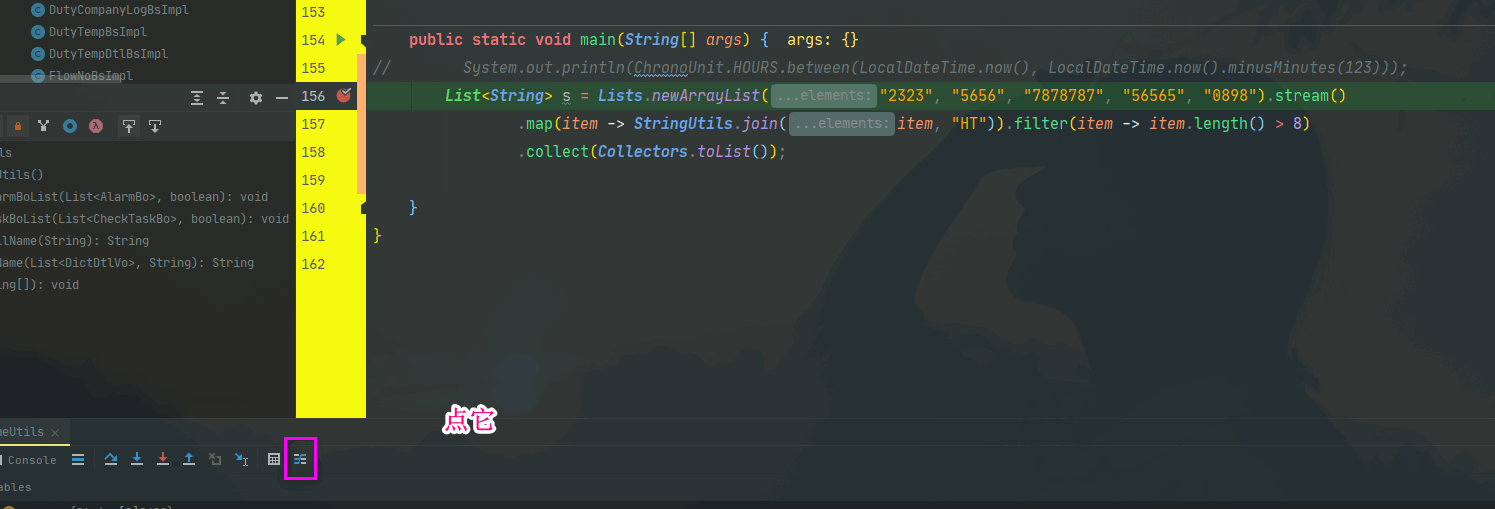
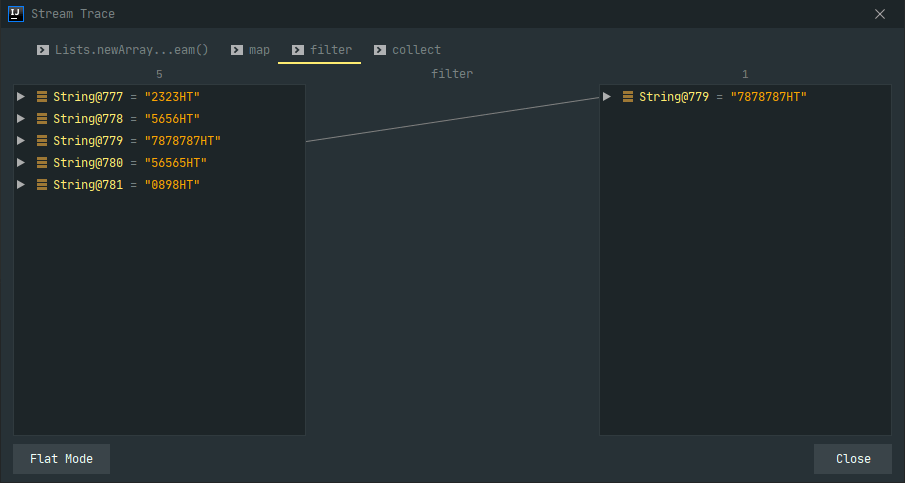
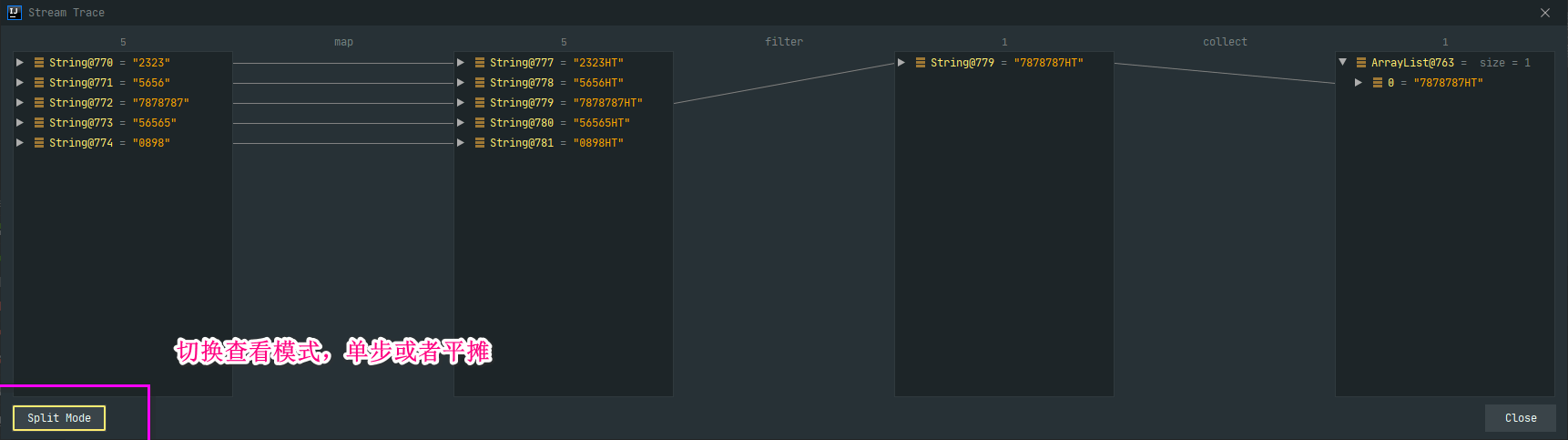
# 性能如何及评测工具推荐
# 实验一_基本类型迭代
基本测试方案,先初始化一个
int数组,5亿个随机数。然后从这个数组中找到最小的一个数
采用三个单元测试方法来对照参考:
- testIntFor方法测试for循环执行时间;
- testIntStream方法测试串行Stream执行时间;
- testIntParallelStream方法测试并行Stream执行时间;
public class StreamTest {
public static int[] arr;
@BeforeAll
public static void init() {
arr = new int[500000000];
randomInt(arr);
}
@JunitPerfConfig(duration = 10000, warmUp = 1000, reporter = {HtmlReporter.class})
public void testIntFor() {
minIntFor(arr);
}
@JunitPerfConfig(duration = 10000, warmUp = 1000, reporter = {HtmlReporter.class})
public void testIntParallelStream() {
minIntParallelStream(arr);
}
@JunitPerfConfig(duration = 10000, warmUp = 1000, reporter = {HtmlReporter.class})
public void testIntStream() {
minIntStream(arr);
}
private int minIntStream(int[] arr) {
return Arrays.stream(arr).min().getAsInt();
}
private int minIntParallelStream(int[] arr) {
return Arrays.stream(arr).parallel().min().getAsInt();
}
private int minIntFor(int[] arr) {
int min = Integer.MAX_VALUE;
for (int anArr : arr) {
if (anArr < min) {
min = anArr;
}
}
return min;
}
private static void randomInt(int[] arr) {
Random r = new Random();
for (int i = 0; i < arr.length; i++) {
arr[i] = r.nextInt();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
@JunitPerfConfig
@JunitPerfConfig(duration = 10000, warmUp = 1000, reporter = {HtmlReporter.class})此注解:该注释为junitperf提供的注解,其中duration为持续执行这段代码的时间,单位毫秒;warmUp预热时间,这里预热1秒;reporter输出报表格式,这里采用HTML展示,可以更直观看到效果
针对基础类型(int)操作,结果分析:
- 串行Stream的执行的确不如for循环性能高,耗时大概是for循环的2倍。
- 并行Stream的执行性能要优于for循环,耗时大概是for循环的一半。
这里没有用不同核数的机器测试,但并行Stream随着服务器核数的增加,必然更快
# 实验二_对象迭代
生成一个List列表,列表中随机生成1千万个字符串,然后分别通过不同的方式计算获得最小的字符串.
针对对象(String)操作,结果分析:
- Stream的性能与for循环已经相差不大了,耗时大概是for循环的1.25倍左右。
- 并行Stream执行的性能要优于for循环,而且比基础类型的优势更高,耗时已经低于for循环的一半。
针对不同服务器核数,Stream效率同样会更加高
# 实验三_复杂对象归约
生成一个List列表,列表里面存放着1百万个User对象。每个对象中都包含用户名和用户某次运动的距离,同一用户可在List里包含多条运动记录。现在通过不同的方式来统计用户的总共运动了多远距离。
基本测试思路一致,这里只贴出基于Stream的算法的代码,以便大家了解Stream的复杂对象归约如何使用。
// 串行写法
users.stream().collect(
Collectors.groupingBy(User::getUserName,
Collectors.summingDouble(User::getMeters)));
// 并行写法
users.parallelStream().collect(
Collectors.groupingBy(User::getUserName,
Collectors.summingDouble(User::getMeters)));
2
3
4
5
6
7
8
复杂对象归约操作,结果分析:
- 基于Stream的操作明显都高于for循环的效率,而且并行的效果更加明显。
- 同样,随着服务器核数的增加,并行Stream的效率会更高。
# 性能测试工具推荐
# Stream相关概念
Stream相关概念
- 元素:特定类型的对象,比如List里面放置的对象,会形成一个队列。Stream不会存储元素,只是按需计算。
- 数据源:流的来源,对照上图中的集合,数组,I/O channel, 产生器generator等。
- 聚合操作:类似SQL语句的各种过滤操作,对照上图中的filter、sorted、map等。
- Pipelining:中文词义“流水线”,中间操作会返回流本身,跟我们之前所说的流式(fluent)编程一个概念,这样可对操作进行优化,比如延迟执行(laziness)和短路(short-circuiting)。
- 内部迭代:传统遍历方式是通过Iterator或For-Each来完成,这是外部迭代。而Stream通过访问者模式(Visitor)实现了内部迭代。
# stream操作方法分类
- 中间聚合操作:
map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 skip、 parallel、 sequential、 unordered。 - 最终输出操作:
forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、iterator。 - 短路操作:
anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 limit
# stream的创建方式
# Stream_of可变参数
Stream<String> stream1 = Stream.of("A", "B", "C");
System.out.println("stream1:" + stream1.collect(joining()));
2
# Stream_of数组
String[] values = new String[]{"A", "B", "C"};
Stream<String> stream2 = Stream.of(values);
System.out.println("stream2:" + stream2.collect(joining()));
2
3
看 Stream.of 源码,上面这两种方式其实就是第三种方式的包装版。
public static<T> Stream<T> of(T... values) {
return Arrays.stream(values);
}
2
3
我们直接使用源码中的方式也是一样的。
# Arrays_stream
String[] values = new String[]{"A", "B", "C"};
Stream<String> stream3 = Arrays.stream(values);
System.out.println("stream3:" + stream3.collect(joining()));
2
3
# List
List<String> list = Arrays.asList("A", "B", "C");
Stream<String> stream4 = list.stream();
System.out.println("stream4:" + stream4.collect(joining()));
2
3
# Set
Set<String> set = new HashSet<>(Arrays.asList("A", "B", "C"));
Stream<String> stream5 = set.stream();
System.out.println("stream5:" + stream5.collect(joining()));
2
3
# Map
Map<String, String> map = new HashMap<>();
map.put("1", "A");
map.put("2", "B");
map.put("3", "C");
Stream<String> stream6 = map.values().stream();
System.out.println("stream6:" + stream6.collect(joining()));
2
3
4
5
6
# Stream_iterate
上面的方法可以认为种子(seed)为"A",f(seed)为在1的基础上“+1”,依次循环下去,直到达到limit的限制,最后生成对应的Stream
Stream<String> stream7 = Stream.iterate("A", e -> String.valueOf((char) (e.charAt(0) + 1))).limit(3);
System.out.println("stream7:" + stream7.collect(joining()));
2
# Pattern
String value = "A B C";
Stream<String> stream8 = Pattern.compile("\\W").splitAsStream(value);
System.out.println("stream8:" + stream8.collect(joining()));
2
3
# Files.lines
try {
Stream<String> stream9 = Files.lines(Paths.get("d:/data.txt"));
System.out.println("stream9:" + stream9.collect(joining()));
} catch (IOException e) {
e.printStackTrace();
}
2
3
4
5
6
# Stream_generate
生成的是无限长度的Stream,其元素是由Supplier接口提供的
Stream<String> stream10 = Stream.generate(() -> "A").limit(3);
System.out.println("stream10:" + stream10.collect(joining()));
2
# empty
empty方法生成一个空的Stream,不包含任何元素
# collect(toList())
collect(toList()) 方法由Stream 里的值生成一个列表,是一个及早求值操作。
Stream 的of 方法使用一组初始值生成新的Stream。
形象一点儿的话,可以将Stream 想象成汉堡,将最前和最后对Stream 操作的方法想象成 两片面包,这两片面包帮助我们认清操作的起点和终点。
List<String> sp = players.stream().filter(str->{
System.out.println(str);
return str.startsWith("N");
}).collect(Collectors.toList());
List<String> s = Stream.of(atp).filter(str->{
System.out.println(str);
return str.startsWith("R");
}).collect(Collectors.toList());
2
3
4
5
6
7
8
# map
如果有一个函数可以将一种类型的值转换成另外一种类型,map 操作就可以使用该函数,将一个流中的值转换成一个新的流。
List<String> sp = players.stream().filter(str->{
System.out.println(str);
return str.startsWith("N");
}).map(str->str.substring(0,3)).collect(Collectors.toList());
sp.forEach((palyer) -> System.out.println(palyer+"。"));
2
3
4
5
# stream-filter
该模式的核心思想是保留Stream中的一些元素,而过滤掉其他的。
Predicate
# stream-flatMap
将流中的每一个元素映射为一个流,再把每一个流连接成为一个流。期间原有的Stream的元素会被逐一替换。官方提供了三种原始类型的变种方法:
flatMapToInt,flatMapToLong和flatMapToDouble
flatMap 方法可用Stream 替换值, 然后将多个Stream 连接成一个Stream。
- 1、顾名思义,跟map差不多,更深层次的操作
- 2、但还是有区别的
- 3、map和flat返回值不同
- 4、Map 每个输入元素,都按照规则转换成为另外一个元素。还有一些场景,是一对多映射关系的,这时需要 flatMap。
- 5、Map一对一
- 6、Flatmap一对多
- 7、map和flatMap的方法声明是不一样的
- (1)
<r> Stream<r> map(Function mapper); - (2)
<r> Stream<r> flatMap(Function> mapper); - (3) map和flatMap的区别:我个人认为,flatMap的可以处理更深层次的数据,入参为多个list,结果可以返回为一个list,而map是一对一的,入参是多个list,结果返回必须是多个list。通俗的说,如果
入参都是对象,那么flatMap可以操作对象里面的对象,而map只能操作第一层。
- (1)
List<Integer> together = Stream.of(asList(1, 2), asList(3, 4))
.flatMap(numbers -> numbers.stream())
.collect(toList());
assertEquals(asList(1, 2, 3, 4), together);
2
3
4
调用stream 方法, 将每个列表转换成Stream 对象, 其余部分由flatMap 方法处理。 flatMap 方法的相关函数接口和map 方法的一样,都是Function 接口,只是方法的返回值 限定为Stream 类型罢了。
# max和min
下面这个静态方法,有用了。
# comparing
需要传给它一个Comparator 对象。
Java 8 提供了一个新的静态方法comparing,使用它可以方便地实现一个比较器。
放在以前,我们
需要比较两个对象的某项属性的值,现在只需要提供一个存取方法就够了。本例中使用getLength 方法。
# skip
跳过前N个元素,取剩余元素
Stream.of(1, 2, 3).skip(2).forEach(System.out::println);//3
# limit
限制返回前N个元素,与SQL中的limit相似
Stream.of(1, 2, 3).limit(2).forEach(System.out::println);//1,2
# sorted
对Stream元素进行排序,可采用默认的sorted()方法进行排序,也可通过sorted(Comparator)方法自定义比较器来进行排序,前者默认调用equals方法来进行比较。
- Comparator.comparing(类::属性一).reversed();
- Comparator.comparing(类::属性一,Comparator.reverseOrder());
//返回 对象集合以类属性一升序排序
list.stream().sorted(Comparator.comparing(类::属性一));
//返回 对象集合以类属性一降序排序 注意两种写法
list.stream().sorted(Comparator.comparing(类::属性一).reversed());//先以属性一升序,结果进行属性一降序
list.stream().sorted(Comparator.comparing(类::属性一,Comparator.reverseOrder()));//以属性一降序
//返回 对象集合以类属性一升序 属性二升序
list.stream().sorted(Comparator.comparing(类::属性一).thenComparing(类::属性二));
//返回 对象集合以类属性一降序 属性二升序 注意两种写法
list.stream().sorted(Comparator.comparing(类::属性一).reversed().thenComparing(类::属性二));//先以属性一升序,升序结果进行属性一降序,再进行属性二升序
list.stream().sorted(Comparator.comparing(类::属性一,Comparator.reverseOrder()).thenComparing(类::属性二));//先以属性一降序,再进行属性二升序
//返回 对象集合以类属性一降序 属性二降序 注意两种写法
list.stream().sorted(Comparator.comparing(类::属性一).reversed().thenComparing(类::属性二,Comparator.reverseOrder()));//先以属性一升序,升序结果进行属性一降序,再进行属性二降序
list.stream().sorted(Comparator.comparing(类::属性一,Comparator.reverseOrder()).thenComparing(类::属性二,Comparator.reverseOrder()));//先以属性一降序,再进行属性二降序
//返回 对象集合以类属性一升序 属性二降序 注意两种写法
list.stream().sorted(Comparator.comparing(类::属性一).reversed().thenComparing(类::属性二).reversed());//先以属性一升序,升序结果进行属性一降序,再进行属性二升序,结果进行属性一降序属性二降序
list.stream().sorted(Comparator.comparing(类::属性一).thenComparing(类::属性二,Comparator.reverseOrder()));//先以属性一升序,再进行属性二降序<br><br><br>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# concat
合并两个Stream。如果
输入Stream有序,则新Stream有序;如果其中一个Stream为并行,则新Stream为并行;如果关闭新Stream,原Stream都将执行关闭
Stream.concat(Stream.of("欢迎","你的"),Stream.of("程序")).forEach(System.out::println);
# distinct
Stream中元素去重
Stream.of(1,1,1).distinct().forEach(System.out::println);
# forEach函数
foreach()处理集合时不能使用break和continue这两个方法,也就是说不能按照普通的for循环遍历集合时那样根据条件来中止遍历;
可以使用return来达到,也就是说如果你在一个方法的lambda表达式中使用return时,这个方法是不会返回的,而只是执行下一次遍历(可以看出return起到的作用和continue是相同的。)
不管你遍历到哪个集合中的元素,上图都会停在第一行程序中而不会发生跳转,所以是不会停止lambda表达式的执行的
# forEachOrder
遍历Stream中所有元素,如果Stream设置了顺序,则按照顺序执行(Stream是无序的),默认为元素的插入顺序
# allMatch
判断Stream中的所有元素是否满足指定条件。全部满足返回true,否则返回false。
boolean result = Stream.of(1, 2, 3).allMatch(i -> i > 0);
System.out.println(result);//true
2
# anyMatch
判断Stream中的元素至少有一个满足指定条件。如果至少有一个满足则返回true,否则返回false。
boolean anyResult = Stream.of(1, 2, 3).anyMatch(i -> i > 2);
System.out.println(anyResult);//true
2
# noneMatch
判断Stream中是否所有元素都不满足指定条件。都不满足则返回true,否则false。
# findAny
获得其中一个元素(使用stream()时找到的是第一个元素;使用parallelStream()并行时找到的是其中一个元素)。如果Stream为空,则返回一个为空的Optional。
Optional<String> any = Stream.of("A", "B", "C").findAny();
System.out.println(any.get());//A
2
# findFirst
获得第一个元素。如果Stream为空,则返回一个为空的Optional。
Optional<String> first = Stream.of("A", "B", "C").findFirst();
System.out.println(first.get());
2
# 统计
通过summaryStatistics方法可获得Stream的一些统计信息。
IntSummaryStatistics summaryStatistics = Stream.of(1, 2, 3).mapToInt((i) -> i).summaryStatistics();
System.out.println("max:" + summaryStatistics.getMax());
System.out.println("min:" + summaryStatistics.getMin());
System.out.println("sum:" + summaryStatistics.getSum());
System.out.println("average:" + summaryStatistics.getAverage());
2
3
4
5