# JVM
# 语言无关性
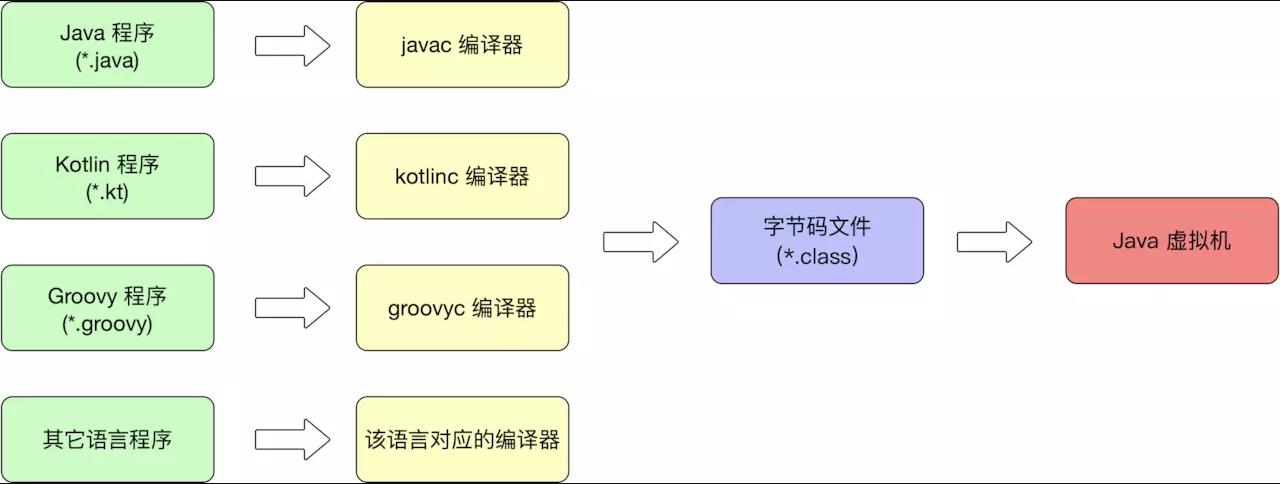
Java 虚拟机的设计者在设计之初就考虑并实现了其它语言在 Java 虚拟机上运行的可能性。
所以并不是只有 Java 语言能够跑在 Java 虚拟机上,时至今日诸如 Kotlin、Groovy、Jython、JRuby 等一大批 JVM 语言都能够在 Java 虚拟机上运行。
它们和 Java 语言一样都会被编译器编译成字节码文件,然后由虚拟机来执行。所以说类文件(字节码文件)具有语言无关性。
# Class文件结构
Class 文件是一组以 8 位字节为基础单位的二进制流,各个数据严格按照顺序紧凑的排列在 Class 文件中,中间无任何分隔符,这使得整个 Class 文件中存储的内容几乎全部都是程序运行的必要数据,没有空隙存在。
当遇到需要占用 8 位字节以上空间的数据项时,会按照高位在前的方式分割成若干个 8 位字节进行存储。
Java 虚拟机规范规定 Class 文件格式采用一种类似与 C 语言结构体的微结构体来存储数据,这种伪结构体中只有两种数据类型:无符号数和表。
- 无符号数
属于基本的数据类型,以 u1、u2、u4、u8来分别代表 1 个字节、2 个字节、4 个字节和 8 个字节的无符号数,无符号数可以用来描述数字、索引引用、数量值或者按照 UTF-8 编码结构构成的字符串值。
- 表
是由多个无符号数或者其他表作为数据项构成的复合数据类型,所有表都习惯性地以「_info」结尾。表用于描述有层次关系的复合结构的数据,整个 Class 文件就是一张表,它由下表中所示的数据项构成。
| 类型 | 名称 | 数量 |
|---|---|---|
| u4 | magic | 1 |
| u2 | minor_version | 1 |
| u2 | major_version | 1 |
| u2 | constant_pool_count | 1 |
| cp_info | constant_pool | constant_pool_count-1 |
| u2 | access_flags | 1 |
| u2 | this_class | 1 |
| u2 | super_class | 1 |
| u2 | interfaces_count | 1 |
| u2 | interfaces | interfaces_count |
| u2 | fields_count | 1 |
| field_info | fields | fields_count |
| u2 | methods_count | 1 |
| method_info | methods | methods_count |
| u2 | attributes_count | 1 |
| attribute_info | attributes | attributes_count |
Class 文件中存储的字节严格按照上表中的顺序紧凑的排列在一起。哪个字节代表什么含义,长度是多少,先后顺序如何都是被严格限制的,不允许有任何改变。
# 2.1魔数与Class文件版本
每个 Class 文件的头 4 个字节称为魔数(Magic Number),它的唯一作用是确定这个文件是否为一个能被虚拟机接收的 Calss 文件。之所以使用魔数而不是文件后缀名来进行识别主要是基于安全性的考虑,因为文件后缀名是可以随意更改的。Class 文件的魔数值为「0xCAFEBABE」。
紧接着魔数的 4 个字节存储的是 Class 文件的版本号:第 5 和第 6 两个字节是次版本号(Minor Version),第 7 和第 8 个字节是主版本号(Major Version)。高版本的 JDK 能够向下兼容低版本的 Class 文件,虚拟机会拒绝执行超过其版本号的 Class 文件。
# 2.2常量池
主版本号之后是常量池入口,常量池可以理解为 Class 文件之中的资源仓库,它是 Class 文件结构中与其他项目关联最多的数据类型,也是占用 Class 文件空间最大的数据项目之一,同是它还是 Class 文件中第一个出现的表类型数据项目。
因为常量池中常量的数量是不固定的,所以在常量池入口需要放置一个 u2 类型的数据来表示常量池的容量「constant_pool_count」,和计算机科学中计数的方法不一样,这个容量是从 1 开始而不是从 0 开始计数。之所以将第 0 项常量空出来是为了满足后面某些指向常量池的索引值的数据在特定情况下需要表达「不引用任何一个常量池项目」的含义,这种情况可以把索引值置为 0 来表示。
Class 文件结构中只有常量池的容量计数是从 1 开始的,其它集合类型,包括接口索引集合、字段表集合、方法表集合等容量计数都是从 0 开始。
常量池中主要存放两大类常量:字面量和符号引用。
字面量比较接近 Java 语言层面的常量概念,如字符串、声明为 final 的常量值等。
符号引用属于编译原理方面的概念,包括了以下三类常量:
- 类和接口的全限定名
- 字段的名称和描述符
- 方法的名称和描述符
# 2.3访问标志
紧接着常量池之后的两个字节代表访问标志(access_flag),这个标志用于识别一些类或者接口层次的访问信息,包括这个 Class 是类还是接口;是否定义为 public 类型;是否定义为 abstract 类型;如果是类的话,是否被申明为 final等。具体的标志位以及标志的含义见下表:
| 标志名称 | 标志值 | 含义 |
|---|---|---|
| ACC_PUBLIC | 0x0001 | 是否为 public 类型 |
| ACC_FINAL | 0x0010 | 是否被声明为 final,只有类可设置 |
| ACC_SUPER | 0x0020 | 是否允许使用 invokespecial 字节码指令的新语意,invokespecial 指令的语意在 JKD 1.0.2 中发生过改变,微聊区别这条指令使用哪种语意,JDK 1.0.2 编译出来的类的这个标志都必须为真 |
| ACC_INTERFACE | 0x0200 | 标识这是一个接口 |
| ACC_ABSTRACT | 0x0400 | 是否为 abstract 类型,对于接口或者抽象类来说,此标志值为真,其它类值为假 |
| ACC_SYNTHETIC | 0x1000 | 标识这个类并非由用户代码产生 |
| ACC_ANNOTATION | 0x2000 | 标识这是一个注解 |
| ACC_ENUM | 0x4000 | 标识这是一个枚举 |
access_flags 中一共有 16 个标志位可以使用,当前只定义了其中的 8 个,没有使用到的标志位要求一律为 0。
# 2.4类索引、父类索引与接口索引集合
类索引(this_class)和父类索引(super_class)都是一个 u2 类型的数据,而接口索引集合(interfaces)是一组 u2 类型的数据集合,Class 文件中由这三项数据来确定这个类的继承关系。
类索引用于确定这个类的全限定名 父类索引用于确定这个类的父类的全限定名 接口索引集合用于描述这个类实现了哪些接口
# 2.5字段表集合
字段表集合(field_info)用于描述接口或者类中声明的变量。字段(field)包括类变量和实例变量,但不包括方法内部声明的局部变量。下面我们看看字段表的结构:
| 类型 | 名称 | 数量 |
|---|---|---|
| u2 | access_flag | 1 |
| u2 | name_index | 1 |
| u2 | descriptor_index | 1 |
| u2 | attributes_count | 1 |
| attribute_info | attributes | attributes_count |
字段修饰符放在 access_flags 中,它与类中的 access_flag 非常相似,都是一个 u2 的数据类型。
| 标志名称 | 标志值 | 含义 |
|---|---|---|
| ACC_PUBLIC | 0x0001 | 字段是否为 public |
| ACC_PRIVATE | 0x0002 | 字段是否为 private |
| ACC_PROTECTED | 0x0004 | 字段是否为 protected |
| ACC_STATIC | 0x0008 | 字段是否为 static |
| ACC_FINAL | 0x0010 | 字段是否为 final |
| ACC_VOLATILE | 0x0040 | 字段是否为 volatile |
| ACC_TRANSIENT | 0x0080 | 字段是否为 transient |
| ACC_SYNTHETIC | 0x1000 | 字段是否由编译器自动生成 |
| ACC_ENUM | 0x4000 | 字段是否为 enum |
# 2.6方法表集合
Class 文件中对方法的描述和对字段的描述是完全一致的,方法表中的结构和字段表的结构一样。 因为 volatile 关键字和 transient 关键字不能修饰方法,所以方法表的访问标志中没有 ACC_VOLATILE 和 ACC_TRANSIENT。与之相对的,synchronizes、native、strictfp 和 abstract 关键字可以修饰方法,所以方法表的访问标志中增加了 ACC_SYNCHRONIZED、ACC_NATIVE、ACC_STRICTFP 和 ACC_ABSTRACT 标志。 对于方法里的代码,经过编译器编译成字节码指令后,存放在方法属性表中一个名为「Code」的属性里面。
# 2.7属性表集合
在 Class 文件、字段表、方法表中都可以携带自己的属性表(attribute_info)集合,用于描述某些场景专有的信息。
属性表集合不像 Class 文件中的其它数据项要求这么严格,不强制要求各属性表的顺序,并且只要不与已有属性名重复,任何人实现的编译器都可以向属性表中写入自己定义的属性信息,Java 虚拟机在运行时会略掉它不认识的属性。
# JVM 中发生内存溢出的 8 种原因及解决办法
# Java堆空间
发生频率:5颗星
造成原因
- 无法在 Java 堆中分配对象
- 吞吐量增加
- 应用程序无意中保存了对象引用,对象无法被 GC 回收
- 应用程序过度使用 finalizer。finalizer 对象不能被 GC 立刻回收。finalizer 由结束队列服务的守护线程调用,有时 finalizer 线程的处理- 能力无法跟上结束队列的增长
解决方案
- 使用 -Xmx 增加堆大小
- 修复应用程序中的内存泄漏
# GC开销超过限制
发生频率:5颗星
造成原因
- Java 进程98%的时间在进行垃圾回收,恢复了不到2%的堆空间,最后连续5个(编译时常量)垃圾回收一直如此。
解决方案
- 使用 -Xmx 增加堆大小
- 使用 -XX:-UseGCOverheadLimit 取消 GC 开销限制
- 修复应用程序中的内存泄漏
# 请求的数组大小超过虚拟机限制
发生频率:2颗星
造成原因
- 应用程序试图分配一个超过堆大小的数组
解决方案
- 使用 -Xmx 增加堆大小
- 修复应用程序中分配巨大数组的 bug
# Perm_gen空间
发生频率:3颗星
造成原因
- Perm gen 空间包含:
类的名字、字段、方法
与类相关的对象数组和类型数组 - JIT 编译器优化
当 Perm gen 空间用尽时,将抛出异常。
解决方案
- 使用 -XX: MaxPermSize 增加 Permgen 大小
- 不重启应用部署应用程序可能会导致此问题。重启 JVM 解决
# Metaspace
发生频率:3颗星
造成原因
- 从 Java 8 开始 Perm gen 改成了 Metaspace,在本机内存中分配 class 元数据(称为 metaspace)。如果 metaspace 耗尽,则抛出异常
解决方案
- 通过命令行设置 -XX: MaxMetaSpaceSize 增加 metaspace 大小
- 取消 -XX: maxmetsspacedize
- 减小 Java 堆大小,为 MetaSpace 提供更多的可用空间
- 为服务器分配更多的内存
- 可能是应用程序 bug,修复 bug
# 无法新建本机线程
发生频率:5颗星
造成原因
- 内存不足,无法创建新线程。由于线程在本机内存中创建,报告这个错误表明本机内存空间不足
解决方案
- 为机器分配更多的内存
- 减少 Java 堆空间
- 修复应用程序中的线程泄漏。
- 增加操作系统级别的限制
ulimit -a - 用户进程数增大 (-u) 1800
- 使用 -Xss 减小线程堆栈大小
# 杀死进程或子进程
发生频率:1颗星
造成原因
- 内核任务:内存不足结束器,在可用内存极低的情况下会杀死进程
解决方案
- 将进程迁移到不同的机器上
- 给机器增加更多内存
- 与其他 OOM 错误不同,这是由操作系统而非 JVM 触发的。
# 发生stack_trace_with_native_method
发生频率:1颗星
造成原因
- 本机方法(native method)分配失败
- 打印的堆栈跟踪信息,最顶层的帧是本机方法
解决方案
- 使用操作系统本地工具进行诊断
# 定位java问题
https://docs.oracle.com/javase/8/docs/technotes/tools/
# jps
首先,使用 jps 得到 Java 进程列表,这会比使用 ps 来的方便
# jinfo
然后,可以使用 jinfo 打印 JVM 的各种参数
# jvisualvm
然后,启动另一个重量级工具 jvisualvm 观察一下程序,可以在概述面板再次确认 JVM 参数设置成功了
jconsole如果希望看到各个内存区的 GC 曲线图,可以使用 jconsole 观察。jconsole 也是一个综合性图形界面监控工具,比 jvisualvm 更方便的一点是,可以用曲线的形式监控各种数据,包括 MBean 中的属性值
# jstat
同样,如果没有条件使用图形界面(毕竟在 Linux 服务器上,我们主要使用命令行工具),又希望看到 GC 趋势的话,我们可以使用 jstat 工具。
jstat -gcutil 23940 5000 100
其中,S0 表示 Survivor0 区占用百分比,S1 表示 Survivor1 区占用百分比,E 表示 Eden 区占用百分比,O 表示老年代占用百分比,M 表示元数据区占用百分比,YGC 表示年轻代回收次数,YGCT 表示年轻代回收耗时,FGC 表示老年代回收次数,FGCT 表示老年代回收耗时。
# jstack
通过命令行工具 jstack,也可以实现抓取线程栈的操作:
# jcmd
最后,我们来看一下 Java HotSpot 虚拟机的 NMT 功能。
通过 NMT,我们可以观察细粒度内存使用情况,设置 -XX:NativeMemoryTracking=summary/detail 可以开启 NMT 功能,开启后可以使用 jcmd 工具查看 NMT 数据。