# useEffect
警告
useeffect中尽量不要试图去改变依赖数组中的内容,防止不停地渲染组件导致内存溢出
- 🤔如何用useEffect模拟componentDidMount生命周期?
虽然可以使用useEffect(fn, []),但它们并不完全相等。和componentDidMount不一样,useEffect会捕获 props和state。所以即便在回调函数里,你拿到的还是初始的props和state。如果你想得到“最新”的值,你可以使用ref。不过,通常会有更简单的实现方式,所以你并不一定要用ref。
- 🤔 如何正确地在useEffect里请求数据?[]又是什么?
[]表示effect没有使用任何React数据流里的值,因此该effect仅被调用一次是安全的。[]同样也是一类常见问题的来源,也即你以为没使用数据流里的值但其实使用了。你需要学习一些策略(主要是useReducer 和 useCallback)来移除这些effect依赖,而不是错误地忽略它们。
- 🤔 我应该把函数当做effect的依赖吗?
一般建议把
不依赖props和state的函数提到你的组件外面,并且把那些仅被effect使用的函数放到effect里面。如果这样做了以后,你的effect还是需要用到组件内的函数(包括通过props传进来的函数),可以在定义它们的地方用useCallback包一层。为什么要这样做呢?因为这些函数可以访问到props和state,因此它们会参与到数据流中。
- 🤔 为什么有时候会出现无限重复请求的问题?
这个通常发生于你在effect里做数据请求并且没有设置effect依赖参数的情况。没有设置依赖,effect会在每次渲染后执行一次,然后在effect中更新了状态引起渲染并再次触发effect。无限循环的发生也可能是因为你设置的依赖总是会改变。你可以通过
一个一个移除的方式排查出哪个依赖导致了问题。但是,移除你使用的依赖(或者盲目地使用[])通常是一种错误的解决方式。你应该做的是解决问题的根源。举个例子,函数可能会导致这个问题,你可以把它们放到effect里,或者提到组件外面,或者用useCallback包一层。useMemo 可以做类似的事情以避免重复生成对象。
- 🤔 为什么有时候在effect里拿到的是旧的state或prop?
Effect拿到的总是定义它的那次渲染中的props和state。这能够避免一些bugs,但在一些场景中又会有些讨人嫌。对于这些场景,你可以明确地使用可变的ref保存一些值(上面文章的末尾解释了这一点)。如果你觉得在渲染中拿到了一些旧的props和state,且不是你想要的,你很可能遗漏了一些依赖。可以尝试使用这个lint 规则来训练你发现这些依赖。可能没过几天,这种能力会变得像是你的第二天性。
- 每一次渲染都有它自己的 Props and State
- 每一次渲染都有它自己的事件处理函数
- 每次渲染都有它自己的Effects
- 每一次渲染都有它自己的…所有
- 逆潮而动
- 那Effect中的清理又是怎样的呢?
- 同步, 而非生命周期
- 告诉React去比对你的Effects
- 关于依赖项不要对React撒谎
- 如果设置了错误的依赖会怎么样呢?
- 两种诚实告知依赖的方法
- 让Effects自给自足
- 函数式更新 和 Google Docs
- 解耦来自Actions的更新
- 为什么useReducer是Hooks的作弊模式
- 把函数移到Effects里
- 但我不能把这个函数放到Effect里
- 函数是数据流的一部分吗?
- 说说竞态
- 提高水准
# 提高水准
在class组件生命周期的思维模型中,副作用的行为和渲染输出是不同的。UI渲染是被props和state驱动的,并且能确保步调一致,但副作用并不是这样。这是一类常见问题的来源。
而在useEffect的思维模型中,默认都是同步的。副作用变成了React数据流的一部分。对于每一个useEffect调用,一旦你处理正确,你的组件能够更好地处理边缘情况。
然而,用好useEffect的前期学习成本更高。这可能让人气恼。用同步的代码去处理边缘情况天然就比触发一次不用和渲染结果步调一致的副作用更难。
这难免让人担忧如果useEffect是你现在使用最多的工具。不过,目前大抵还处理低水平使用阶段。因为Hooks太新了所以大家都还在低水平地使用它,尤其是在一些教程示例中。但在实践中,社区很可能即将开始高水平地使用Hooks,因为好的API会有更好的动量和冲劲。
我看到不同的应用在创造他们自己的Hooks,比如封装了应用鉴权逻辑的useFetch或者使用theme context的useTheme 。你一旦有了包含这些的工具箱,你就不会那么频繁地直接使用useEffect。但每一个基于它的Hook都能从它的适应能力中得到益处。
目前为止,useEffect主要用于数据请求。但是数据请求准确说并不是一个同步问题。因为我们的依赖经常是[]所以这一点尤其明显。那我们究竟在同步什么?
长远来看, Suspense用于数据请求 会允许第三方库通过第一等的途径告诉React暂停渲染直到某些异步事物(任何东西:代码,数据,图片)已经准备就绪。
当Suspense逐渐地覆盖到更多的数据请求使用场景,我预料useEffect 会退居幕后作为一个强大的工具,用于同步props和state到某些副作用。不像数据请求,它可以很好地处理这些场景因为它就是为此而设计的。不过在那之前,自定义的Hooks比如这儿提到的是复用数据请求逻辑很好的方式。
# 说说竞态
class Article extends Component {
state = {
article: null
};
componentDidMount() {
this.fetchData(this.props.id);
}
async fetchData(id) {
const article = await API.fetchArticle(id);
this.setState({ article });
}
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
你很可能已经知道,上面的代码埋伏了一些问题。它并没有处理更新的情况。所以第二个你能够在网上找到的经典例子是下面这样的:
class Article extends Component {
state = {
article: null
};
componentDidMount() {
this.fetchData(this.props.id);
}
componentDidUpdate(prevProps) {
if (prevProps.id !== this.props.id) {
this.fetchData(this.props.id);
}
}
async fetchData(id) {
const article = await API.fetchArticle(id);
this.setState({ article });
}
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
这显然好多了!但依旧有问题。有问题的原因是请求结果返回的顺序不能保证一致。比如我先请求 {id: 10},然后更新到{id: 20},但{id: 20}的请求更先返回。请求更早但返回更晚的情况会错误地覆盖状态值。
这被叫做竞态,这在混合了async / await(假设在等待结果返回)和自顶向下数据流的代码中非常典型(props和state可能会在async函数调用过程中发生改变)。
Effects并没有神奇地解决这个问题,尽管它会警告你如果你直接传了一个async 函数给effect。(我们会改善这个警告来更好地解释你可能会遇到的这些问题。)
如果你使用的异步方式支持取消,那太棒了。你可以直接在清除函数中取消异步请求。
或者,最简单的权宜之计是用一个布尔值来跟踪它:
function Article({ id }) {
const [article, setArticle] = useState(null);
useEffect(() => {
let didCancel = false;
async function fetchData() {
const article = await API.fetchArticle(id);
if (!didCancel) {
setArticle(article);
}
}
fetchData();
return () => {
didCancel = true;
};
}, [id]);
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
这篇文章讨论了更多关于如何处理错误和加载状态,以及抽离逻辑到自定义的Hook。我推荐你认真阅读一下如果你想学习更多关于如何在Hooks里请求数据的内容。
# 数据流
有趣的是,这种模式在class组件中行不通,并且这种行不通恰到好处地揭示了effect和生命周期范式之间的区别。考虑下面的转换:
class Parent extends Component {
state = {
query: 'react'
};
fetchData = () => {
const url = 'https://hn.algolia.com/api/v1/search?query=' + this.state.query;
// ... Fetch data and do something ...
};
render() {
return <Child fetchData={this.fetchData} />;
}
}
class Child extends Component {
state = {
data: null
};
componentDidMount() {
this.props.fetchData();
}
render() {
// ...
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
你可能会想:“少来了Dan,我们都知道useEffect 就像componentDidMount 和 componentDidUpdate的结合,你不能老是破坏这一条!”好吧,就算加了componentDidUpdate照样无用:
class Child extends Component {
state = {
data: null
};
componentDidMount() {
this.props.fetchData();
}
componentDidUpdate(prevProps) {
// 🔴 This condition will never be true
if (this.props.fetchData !== prevProps.fetchData) {
this.props.fetchData();
}
}
render() {
// ...
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
当然如此,fetchData是一个class方法!(或者你也可以说是class属性 - 但这不能改变什么。)它不会因为状态的改变而不同,所以this.props.fetchData和 prevProps.fetchData始终相等,因此不会重新请求。那我们删掉条件判断怎么样?
componentDidUpdate(prevProps) {
this.props.fetchData();
}
2
3
等等,这样会在每次渲染后都去请求。(添加一个加载动画可能是一种有趣的发现这种情况的方式。)也许我们可以绑定一个特定的query?
render() {
return <Child fetchData={this.fetchData.bind(this, this.state.query)} />;
}
2
3
但这样一来,this.props.fetchData !== prevProps.fetchData 表达式永远是true,即使query并未改变。这会导致我们总是去请求。
想要解决这个class组件中的难题,唯一现实可行的办法是硬着头皮把query本身传入 Child 组件。 Child 虽然实际并没有直接使用这个query的值,但能在它改变的时候触发一次重新请求:
class Parent extends Component {
state = {
query: 'react'
};
fetchData = () => {
const url = 'https://hn.algolia.com/api/v1/search?query=' + this.state.query;
// ... Fetch data and do something ...
};
render() {
return <Child fetchData={this.fetchData} query={this.state.query} />;
}
}
class Child extends Component {
state = {
data: null
};
componentDidMount() {
this.props.fetchData();
}
componentDidUpdate(prevProps) {
if (this.props.query !== prevProps.query) {
this.props.fetchData();
}
}
render() {
// ...
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
在class组件中,函数属性本身并不是数据流的一部分。组件的方法中包含了可变的this变量导致我们不能确定无疑地认为它是不变的。因此,即使我们只需要一个函数,我们也必须把一堆数据传递下去仅仅是为了做“diff”。我们无法知道传入的this.props.fetchData 是否依赖状态,并且不知道它依赖的状态是否改变了。
使用useCallback,函数完全可以参与到数据流中。我们可以说如果一个函数的输入改变了,这个函数就改变了。如果没有,函数也不会改变。感谢周到的useCallback,属性比如props.fetchData的改变也会自动传递下去。
类似的,useMemo可以让我们对复杂对象做类似的事情。
function ColorPicker() {
// Doesn't break Child's shallow equality prop check
// unless the color actually changes.
const [color, setColor] = useState('pink');
const style = useMemo(() => ({ color }), [color]);
return <Child style={style} />;
}
2
3
4
5
6
7
我想强调的是,到处使用useCallback是件挺笨拙的事。当我们需要将函数传递下去并且函数会在子组件的effect中被调用的时候,useCallback 是很好的技巧且非常有用。或者你想试图减少对子组件的记忆负担,也不妨一试。但总的来说Hooks本身能更好地避免传递回调函数。
# 里面
有时候你可能不想把函数移入effect里。比如,组件内有几个effect使用了相同的函数,你不想在每个effect里复制黏贴一遍这个逻辑。也或许这个函数是一个prop。
在这种情况下你应该忽略对函数的依赖吗?我不这么认为。再次强调,effects不应该对它的依赖撒谎。通常我们还有更好的解决办法。一个常见的误解是,“函数从来不会改变”。但是这篇文章你读到现在,你知道这显然不是事实。实际上,在组件内定义的函数每一次渲染都在变。
function SearchResults() {
function getFetchUrl(query) {
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}
useEffect(() => {
const url = getFetchUrl('react');
// ... Fetch data and do something ...
}, []); // 🔴 Missing dep: getFetchUrl
useEffect(() => {
const url = getFetchUrl('redux');
// ... Fetch data and do something ...
}, []); // 🔴 Missing dep: getFetchUrl
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
在这个例子中,你可能不想把getFetchUrl 移到effects中,因为你想复用逻辑。
另一方面,如果你对依赖很“诚实”,你可能会掉到陷阱里。我们的两个effects都依赖getFetchUrl,而它每次渲染都不同,所以我们的依赖数组会变得无用:
function SearchResults() {
// 🔴 Re-triggers all effects on every render
function getFetchUrl(query) {
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}
useEffect(() => {
const url = getFetchUrl('react');
// ... Fetch data and do something ...
}, [getFetchUrl]); // 🚧 Deps are correct but they change too often
useEffect(() => {
const url = getFetchUrl('redux');
// ... Fetch data and do something ...
}, [getFetchUrl]); // 🚧 Deps are correct but they change too often
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
一个可能的解决办法是把getFetchUrl从依赖中去掉。但是,我不认为这是好的解决方式。这会使我们后面对数据流的改变很难被发现从而忘记去处理。这会导致类似于上面“定时器不更新值”的问题。
- 第一个, 如果一个函数没有使用组件内的任何值,你应该把它提到组件外面去定义,然后就可以自由地在effects中使用:
// ✅ Not affected by the data flow
function getFetchUrl(query) {
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}
function SearchResults() {
useEffect(() => {
const url = getFetchUrl('react');
// ... Fetch data and do something ...
}, []); // ✅ Deps are OK
useEffect(() => {
const url = getFetchUrl('redux');
// ... Fetch data and do something ...
}, []); // ✅ Deps are OK
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
你不再需要把它设为依赖,因为它们不在渲染范围内,因此不会被数据流影响。它不可能突然意外地依赖于props或state。
或者, 你也可以把它包装成 useCallback Hook:
function SearchResults() {
// ✅ Preserves identity when its own deps are the same
const getFetchUrl = useCallback((query) => {
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}, []); // ✅ Callback deps are OK
useEffect(() => {
const url = getFetchUrl('react');
// ... Fetch data and do something ...
}, [getFetchUrl]); // ✅ Effect deps are OK
useEffect(() => {
const url = getFetchUrl('redux');
// ... Fetch data and do something ...
}, [getFetchUrl]); // ✅ Effect deps are OK
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
useCallback本质上是添加了一层依赖检查。它以另一种方式解决了问题 - 我们使函数本身只在需要的时候才改变,而不是去掉对函数的依赖。
我们来看看为什么这种方式是有用的。之前,我们的例子中展示了两种搜索结果(查询条件分别为'react'和'redux')。但如果我们想添加一个输入框允许你输入任意的查询条件(query)。不同于传递query参数的方式,现在getFetchUrl会从状态中读取。
我们很快发现它遗漏了query依赖:
function SearchResults() {
const [query, setQuery] = useState('react');
const getFetchUrl = useCallback(() => { // No query argument
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}, []); // 🔴 Missing dep: query
// ...
}
2
3
4
5
6
7
如果我把query添加到useCallback 的依赖中,任何调用了getFetchUrl的effect在query改变后都会重新运行:
function SearchResults() {
const [query, setQuery] = useState('react');
// ✅ Preserves identity until query changes
const getFetchUrl = useCallback(() => {
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}, [query]); // ✅ Callback deps are OK
useEffect(() => {
const url = getFetchUrl();
// ... Fetch data and do something ...
}, [getFetchUrl]); // ✅ Effect deps are OK
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
我们要感谢useCallback,因为如果query 保持不变,getFetchUrl也会保持不变,我们的effect也不会重新运行。但是如果query修改了,getFetchUrl也会随之改变,因此会重新请求数据。这就像你在Excel里修改了一个单元格的值,另一个使用它的单元格会自动重新计算一样。
这正是拥抱数据流和同步思维的结果。对于通过属性从父组件传入的函数这个方法也适用:
function Parent() {
const [query, setQuery] = useState('react');
// ✅ Preserves identity until query changes
const fetchData = useCallback(() => {
const url = 'https://hn.algolia.com/api/v1/search?query=' + query;
// ... Fetch data and return it ...
}, [query]); // ✅ Callback deps are OK
return <Child fetchData={fetchData} />
}
function Child({ fetchData }) {
let [data, setData] = useState(null);
useEffect(() => {
fetchData().then(setData);
}, [fetchData]); // ✅ Effect deps are OK
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
因为fetchData只有在Parent的query状态变更时才会改变,所以我们的Child只会在需要的时候才去重新请求数据。
# 函数移动
一个典型的误解是认为函数不应该成为依赖。举个例子,下面的代码看上去可以运行正常:
function SearchResults() {
const [data, setData] = useState({ hits: [] });
async function fetchData() {
const result = await axios(
'https://hn.algolia.com/api/v1/search?query=react',
);
setData(result.data);
}
useEffect(() => {
fetchData();
}, []); // Is this okay?
// ...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
需要明确的是,上面的代码可以正常工作。但这样做在组件日渐复杂的迭代过程中我们很难确保它在各种情况下还能正常运行。
想象一下我们的代码做下面这样的分离,并且每一个函数的体量是现在的五倍:
# 作弊
我们已经学习到如何移除effect的依赖,不管状态更新是依赖上一个状态还是依赖另一个状态。但假如我们需要依赖props去计算下一个状态呢?举个例子,也许我们的API是<Counter step={1} />。确定的是,在这种情况下,我们没法避免依赖props.step 。是吗?
我们可以避免!我们可以把reducer函数放到组件内去读取props:
function Counter({ step }) {
const [count, dispatch] = useReducer(reducer, 0);
function reducer(state, action) {
if (action.type === 'tick') {
return state + step;
} else {
throw new Error();
}
}
useEffect(() => {
const id = setInterval(() => {
dispatch({ type: 'tick' });
}, 1000);
return () => clearInterval(id);
}, [dispatch]);
return <h1>{count}</h1>;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
这种模式会使一些优化失效,所以你应该避免滥用它,不过如果你需要你完全可以在reducer里面访问props。
import React, { useReducer, useEffect } from "react";
import ReactDOM from "react-dom";
function Counter() {
const [state, dispatch] = useReducer(reducer, initialState);
const { count, step } = state;
useEffect(() => {
const id = setInterval(() => {
dispatch({ type: 'tick' });
}, 1000);
return () => clearInterval(id);
}, [dispatch]);
return (
<>
<h1>{count}</h1>
<input value={step} onChange={e => {
dispatch({
type: 'step',
step: Number(e.target.value)
});
}} />
</>
);
}
const initialState = {
count: 0,
step: 1,
};
function reducer(state, action) {
const { count, step } = state;
if (action.type === 'tick') {
return { count: count + step, step };
} else if (action.type === 'step') {
return { count, step: action.step };
} else {
throw new Error();
}
}
const rootElement = document.getElementById("root");
ReactDOM.render(<Counter />, rootElement);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
即使是在这个例子中,React也保证dispatch在每次渲染中都是一样的。 所以你可以在依赖中去掉它。它不会引起effect不必要的重复执行。
你可能会疑惑:这怎么可能?在之前渲染中调用的reducer怎么“知道”新的props?答案是当你dispatch的时候,React只是记住了action - 它会在下一次渲染中再次调用reducer。在那个时候,新的props就可以被访问到,而且reducer调用也不是在effect里。
这就是为什么我倾向认为useReducer是Hooks的“作弊模式”。它可以把更新逻辑和描述发生了什么分开。结果是,这可以帮助我移除不必需的依赖,避免不必要的effect调用。
# 解耦
我们来修改上面的例子让它包含两个状态:count 和 step。我们的定时器会每次在count上增加一个step值:
function Counter() {
const [count, setCount] = useState(0);
const [step, setStep] = useState(1);
useEffect(() => {
const id = setInterval(() => {
setCount(c => c + step);
}, 1000);
return () => clearInterval(id);
}, [step]);
return (
<>
<h1>{count}</h1>
<input value={step} onChange={e => setStep(Number(e.target.value))} />
</>
);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
这个例子目前的行为是修改step会重启定时器 - 因为它是依赖项之一。在大多数场景下,这正是你所需要的。清除上一次的effect然后重新运行新的effect并没有任何错。除非我们有很好的理由,我们不应该改变这个默认行为。
不过,假如我们不想在step改变后重启定时器,我们该如何从effect中移除对step的依赖呢?
当你想更新一个状态,并且这个状态更新依赖于另一个状态的值时,你可能需要用useReducer去替换它们。
当你写类似setSomething(something => ...)这种代码的时候,也许就是考虑使用reducer的契机。reducer可以让你把组件内发生了什么(actions)和状态如何响应并更新分开表述。
我们用一个dispatch依赖去替换effect的step依赖:
const [state, dispatch] = useReducer(reducer, initialState);
const { count, step } = state;
useEffect(() => {
const id = setInterval(() => {
dispatch({ type: 'tick' }); // Instead of setCount(c => c + step);
}, 1000);
return () => clearInterval(id);
}, [dispatch]);
2
3
4
5
6
7
8
9
你可能会问:“这怎么就更好了?”答案是React会保证dispatch在组件的声明周期内保持不变。所以上面例子中不再需要重新订阅定时器。
相比于直接在effect里面读取状态,它dispatch了一个action来描述发生了什么。这使得我们的effect和step状态解耦。我们的effect不再关心怎么更新状态,它只负责告诉我们发生了什么。更新的逻辑全都交由reducer去统一处理:
const initialState = {
count: 0,
step: 1,
};
function reducer(state, action) {
const { count, step } = state;
if (action.type === 'tick') {
return { count: count + step, step };
} else if (action.type === 'step') {
return { count, step: action.step };
} else {
throw new Error();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 函数式更新
还记得我们说过同步才是理解effects的心智模型吗?同步的一个有趣地方在于你通常想要把同步的“信息”和状态解耦。举个例子,当你在Google Docs编辑文档的时候,Google并不会把整篇文章发送给服务器。那样做会非常低效。相反的,它只是把你的修改以一种形式发送给服务端。
虽然我们effect的情况不尽相同,但可以应用类似的思想。只在effects中传递最小的信息会很有帮助。类似于setCount(c => c + 1)这样的更新形式比setCount(count + 1)传递了更少的信息,因为它不再被当前的count值“污染”。它只是表达了一种行为(“递增”)。“Thinking in React”也讨论了如何找到最小状态。原则是类似的,只不过现在关注的是如何更新。
然而,即使是setCount(c => c + 1)也并不完美。它看起来有点怪,并且非常受限于它能做的事。举个例子,如果我们有两个互相依赖的状态,或者我们想基于一个prop来计算下一次的state,它并不能做到。幸运的是, setCount(c => c + 1)有一个更强大的姐妹模式,它的名字叫useReducer。
# 自给自足
我们想去掉effect的count依赖。
useEffect(() => {
const id = setInterval(() => {
setCount(count + 1);
}, 1000);
return () => clearInterval(id);
}, [count]);
2
3
4
5
6
为了实现这个目的,我们需要问自己一个问题:我们为什么要用count?可以看到我们只在setCount调用中用到了count。在这个场景中,我们其实并不需要在effect中使用count。当我们想要根据前一个状态更新状态的时候,我们可以使用setState的函数形式:
useEffect(() => {
const id = setInterval(() => {
setCount(c => c + 1);
}, 1000);
return () => clearInterval(id);
}, []);
2
3
4
5
6
我喜欢把类似这种情况称为“错误的依赖”。是的,因为我们在effect中写了setCount(count + 1)所以count是一个必需的依赖。但是,我们真正想要的是把count转换为count+1,然后返回给React。可是React其实已经知道当前的count。我们需要告知React的仅仅是去递增状态 - 不管它现在具体是什么值。
注意我们做到了移除依赖,并且没有撒谎。我们的effect不再读取渲染中的count值。
# 诚实
有两种诚实告知依赖的策略。你应该从第一种开始,然后在需要的时候应用第二种。
- 第一种策略是在
依赖中包含所有effect中用到的组件内的值。让我们在依赖中包含count:
useEffect(() => {
const id = setInterval(() => {
setCount(count + 1);
}, 1000);
return () => clearInterval(id);
}, [count]);
2
3
4
5
6
现在依赖数组正确了。虽然它可能不是太理想但确实解决了上面的问题。现在,每次count修改都会重新运行effect,并且定时器中的setCount(count + 1)会正确引用某次渲染中的 count值:
这能解决问题但是我们的定时器会在每一次count改变后清除和重新设定。这应该不是我们想要的结果:
- 第二种策略是
修改effect内部的代码以确保它包含的值只会在需要的时候发生变更。我们不想告知错误的依赖 - 我们只是修改effect使得依赖更少。
# 错误依赖
如果依赖项包含了所有effect中使用到的值,React就能知道何时需要运行它:
useEffect(() => {
document.title = 'Hello, ' + name;
}, [name]);
2
3
但是如果我们将[]设为effect的依赖,新的effect函数不会运行:
# 撒谎
关于依赖项对React撒谎会有不好的结果。直觉上,这很好理解,但我曾看到几乎所有依赖class心智模型使用useEffect的人都试图违反这个规则。
function SearchResults() {
async function fetchData() {
// ...
}
useEffect(() => {
fetchData();
}, []); // Is this okay? Not always -- and there's a better way to write it.
// ...
}
2
3
4
5
6
7
8
9
10
11
“但我只是想在挂载的时候运行它!”,你可能会说。现在只需要记住:如果你设置了依赖项,effect中用到的所有组件内的值都要包含在依赖中。这包括props,state,函数 — 组件内的任何东西。
有时候你是这样做了,但可能会引起一个问题。比如,你可能会遇到无限请求的问题,或者socket被频繁创建的问题。解决问题的方法不是移除依赖项。我们会很快了解具体的解决方案。
# 告知
其实我们已经从React处理DOM的方式中学习到了解决办法。
React只会更新DOM真正发生改变的部分,而不是每次渲染都大动干戈。
function Greeting({ name }) {
const [counter, setCounter] = useState(0);
useEffect(() => {
document.title = 'Hello, ' + name;
});
return (
<h1 className="Greeting">
Hello, {name}
<button onClick={() => setCounter(counter + 1)}>
Increment
</button>
</h1>
);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
但是我们的effect并没有使用counter这个状态。我们的effect只会同步name属性给document.title,但name并没有变。在每一次counter改变后重新给document.title赋值并不是理想的做法。
- 那React可以…区分effects的不同吗?
- 并不能。React并不能猜测到函数做了什么如果不先调用的话
- 这是为什么你如果想要避免effects不必要的重复调用,你可以提供给useEffect一个依赖数组参数(deps):
useEffect(() => {
document.title = 'Hello, ' + name;
}, [name]); // Our deps
2
3
这好比你告诉React:“Hey,我知道你看不到这个函数里的东西,但我可以保证只使用了渲染中的name,别无其他。”
# 同步
喜欢React的一点是它统一描述了初始渲染和之后的更新。这降低了你程序的熵。
function Greeting({ name }) {
return (
<h1 className="Greeting">
Hello, {name}
</h1>
);
}
2
3
4
5
6
7
我先渲染<Greeting name="Dan" />然后渲染<Greeting name="Yuzhi" />,和我直接渲染<Greeting name="Yuzhi" />并没有什么区别。在这两种情况中,我最后看到的都是“Hello, Yuzhi”。
人们总是说:“重要的是旅行过程,而不是目的地”。在React世界中,恰好相反。重要的是目的,而不是过程。这就是JQuery代码中 $.addClass 或 $.removeClass这样的调用(过程)和React代码中声明CSS类名应该是什么(目的)之间的区别。
- React会根据我们当前的props和state同步到DOM。“mount”和“update”之于渲染并没有什么区别。
- 你应该以相同的方式去思考effects。useEffect使你能够根据props和state同步React tree之外的东西。
function Greeting({ name }) {
useEffect(() => {
document.title = 'Hello, ' + name;
});
return (
<h1 className="Greeting">
Hello, {name}
</h1>
);
}
2
3
4
5
6
7
8
9
10
这就是和大家熟知的mount/update/unmount心智模型之间细微的区别。理解和内化这种区别是非常重要的。如果你试图写一个effect会根据是否第一次渲染而表现不一致,你正在逆潮而动。如果我们的结果依赖于过程而不是目的,我们会在同步中犯错。
# 清理
有些 effects 可能需要有一个清理步骤。本质上,它的目的是
消除副作用(effect),比如取消订阅。
useEffect(() => {
ChatAPI.subscribeToFriendStatus(props.id, handleStatusChange);
return () => {
ChatAPI.unsubscribeFromFriendStatus(props.id, handleStatusChange);
};
});
2
3
4
5
6
假设第一次渲染的时候props是{id: 10},第二次渲染的时候是{id: 20}。你可能会认为发生了下面的这些事:
- React 清除了 {id: 10}的effect。
- React 渲染{id: 20}的UI。
- React 运行{id: 20}的effect。
(事实并不是这样。)
React只会在浏览器绘制后运行effects。这使得你的应用更流畅因为大多数effects并不会阻塞屏幕的更新。Effect的清除同样被延迟了。上一次的effect会在重新渲染后被清除:
- React 渲染{id: 20}的UI。
- 浏览器绘制。我们在屏幕上看到{id: 20}的UI。
- React 清除{id: 10}的effect。
- React 运行{id: 20}的effect。
你可能会好奇:如果清除上一次的effect发生在props变成{id: 20}之后,那它为什么还能“看到”旧的{id: 10}?
清除的是什么
前面得到的结论:组件内的每一个函数(包括事件处理函数,effects,定时器或者API调用等等)会捕获定义它们的那次渲染中的props和state。
清除的是什么
effect的清除并不会读取“最新”的props。它只能读取到定义它的那次渲染中的props值:
// First render, props are {id: 10}
function Example() {
// ...
useEffect(
// Effect from first render
() => {
ChatAPI.subscribeToFriendStatus(10, handleStatusChange);
// Cleanup for effect from first render
return () => {
ChatAPI.unsubscribeFromFriendStatus(10, handleStatusChange);
};
}
);
// ...
}
// Next render, props are {id: 20}
function Example() {
// ...
useEffect(
// Effect from second render
() => {
ChatAPI.subscribeToFriendStatus(20, handleStatusChange);
// Cleanup for effect from second render
return () => {
ChatAPI.unsubscribeFromFriendStatus(20, handleStatusChange);
};
}
);
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
但是第一次渲染中effect的清除函数只能看到{id: 10}这个props。
这正是为什么React能做到在绘制后立即处理effects — 并且默认情况下使你的应用运行更流畅。如果你的代码需要依然可以访问到老的props。
# 逆潮而动
每一个组件内的函数(包括事件处理函数,effects,定时器或者API调用等等)会捕获某次渲染中定义的props和state。
在组件内什么时候去读取props或者state是无关紧要的。因为它们不会改变。在单次渲染的范围内,props和state始终保持不变。
当然,有时候你可能想在effect的回调函数里读取最新的值而不是捕获的值。最简单的实现方法是使用refs,
需要注意的是当你想要从过去渲染中的函数里读取未来的props和state,你是在逆潮而动。虽然它并没有错(有时候可能也需要这样做),但它因为打破了默认范式会使代码显得不够“干净”。这是我们有意为之的,因为它能帮助突出哪些代码是脆弱的,是需要依赖时间次序的。在class中,如果发生这种情况就没那么显而易见了。
function Example() {
const [count, setCount] = useState(0);
const latestCount = useRef(count);
useEffect(() => {
// Set the mutable latest value
latestCount.current = count;
setTimeout(() => {
// Read the mutable latest value
console.log(`You clicked ${latestCount.current} times`);
}, 3000);
});
// ...
2
3
4
5
6
7
8
9
10
11
12
13
在React中去直接修改值看上去有点怪异。然而,在class组件中React正是这样去修改this.state的。不像捕获的props和state,你没法保证在任意一个回调函数中读取的latestCount.current是不变的。根据定义,你可以随时修改它。这就是为什么它不是默认行为,而是需要你主动选择这样做。
# 所有
我们现在知道effects会在每次渲染后运行,并且概念上它是组件输出的一部分,可以“看到”属于某次特定渲染的props和state。
function Counter() {
const [count, setCount] = useState(0);
useEffect(() => {
setTimeout(() => {
console.log(`You clicked ${count} times`);
}, 3000);
});
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
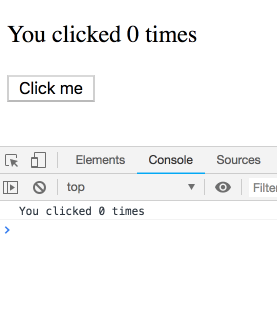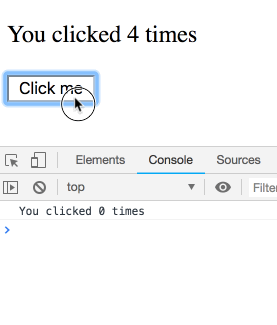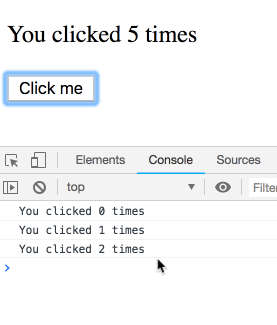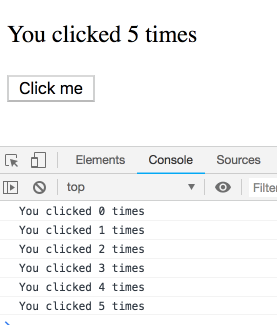
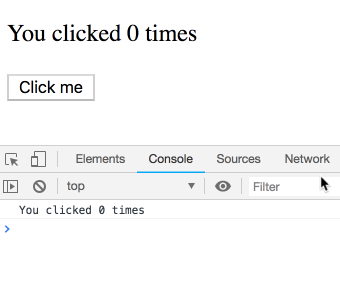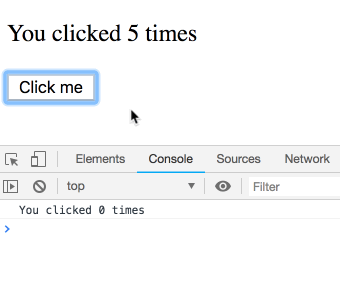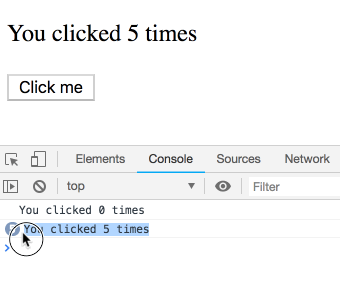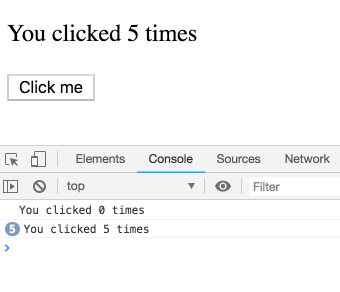
不过,class中的this.state并不是这样运作的。你可能会想当然以为下面的class 实现和上面是相等的:
componentDidUpdate() {
setTimeout(() => {
console.log(`You clicked ${this.state.count} times`);
}, 3000);
}
2
3
4
5
然而,this.state.count总是指向最新的count值,而不是属于某次特定渲染的值。所以你会看到每次打印输出都是5:
当然我们可以用闭包解决这个问题
componentDidUpdate() {
const count = this.state.count;
setTimeout(() => {
console.log(`You clicked ${count} times`);
}, 3000);
}
2
3
4
5
6
# 自己的Effects
function Counter() {
const [count, setCount] = useState(0);
useEffect(() => {
document.title = `You clicked ${count} times`;
});
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
- effect是如何读取到最新的count 状态值的呢?
- 是某种“data binding”或“watching”机制使得count能够在effect函数内更新?也或许count是一个可变的值,React会在我们组件内部修改它以使我们的effect函数总能拿到最新的值?都不是。。。。
我们已经知道count是某个特定渲染中的常量。事件处理函数“看到”的是属于它那次特定渲染中的count状态值。对于effects也同样如此:
并不是count的值在“不变”的effect中发生了改变,而是effect 函数本身在每一次渲染中都不相同。概念上,你可以想象effects是渲染结果的一部分。
# 事件处理函数
function Counter() {
const [count, setCount] = useState(0);
function handleAlertClick() {
setTimeout(() => {
alert('You clicked on: ' + count);
}, 3000);
}
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
<button onClick={handleAlertClick}>
Show alert
</button>
</div>
);
}
//正确alert——3:alert会“捕获”我点击按钮时候的状态。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
- 点击增加counter到3
- 点击一下 “Show alert”
- 点击增加 counter到5并且在定时器回调触发前完成
我们发现count在每一次函数调用中都是一个常量值。值得强调的是 — 我们的组件函数每次渲染都会被调用,但是每一次调用中count值都是常量,并且它被赋予了当前渲染中的状态值。每一次渲染“看到”的是它自己的count:
所以实际上,每一次渲染都有一个“新版本”的handleAlertClick。每一个版本的handleAlertClick“记住” 了它自己的 count:
在任意一次渲染中,props和state是始终保持不变的。如果props和state在不同的渲染中是相互独立的,那么使用到它们的任何值也是独立的(包括事件处理函数)。它们都“属于”一次特定的渲染。即便是事件处理中的异步函数调用“看到”的也是这次渲染中的count值。
通过调用setSomething(newObj)的方式去生成一个新的对象而不是直接修改它是更好的选择,因为这样能保证之前渲染中的state不会被污染。
# 有它自己的
function Counter() {
const [count, setCount] = useState(0);
return (
<div>
<!-- 注意下面这行 -->
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}
2
3
4
5
6
7
8
9
10
11
12
13
它仅仅只是在渲染输出中插入了count这个数字。这个数字由React提供。当setCount的时候,React会带着一个不同的count值再次调用组件。然后,React会更新DOM以保持和渲染输出一致。
这里关键的点在于任意一次渲染中的count常量都不会随着时间改变。渲染输出会变是因为我们的组件被一次次调用,而每一次调用引起的渲染中,它包含的count值独立于其他渲染。