# XML
# xml中语句判断的问题
# 待判断的常量字符串如果2个以上(含2个)字符时则可使用单引号
当然使用双引号肯定更没问题
<if test="param.searchType=='01'">
</if>
2
# 带判断的常量字符串只有1个字符或者空字符串时,不可使用单引号
此时java会将其解析成char类型,将会导致
==的判断无法按照预期
此时需要将判断的句子中的单个字符必须是双引号"包裹,外层套单引号'
<if test='@com.fourfaith.base.mybatis.Ognl@isNotEmpty(params.searchType) and params.searchType=="2"'>
</if>
<when test='params.status == "0"'>
l.${fire}STATUS = #{params.status} or l.${fire}STATUS ='1'
</when>
2
3
4
5
6
# XML文件加载顺序
从我标记的三个重点加上小学简单的英文就可以看出,在解析
UserPersonalMapper.xml时,没有找到BaseResultMap,
另外一点,从我标记中的重点中也可以看出,这个BaseResultMap是在另外一个XML,也就是UserMapper.xml中声明的. 这个时候可能就有朋友想到,那是不是加载UserPersonalMapper.xml的时候,UserMapper.xml还没加载导致的呢.导致无法找到UserMapper.xml定义的BaseResultMap,
坦白说,这个猜测,一点毛病都没有,非常合情合理. 然后你本地启动,和jar启动,看日志输出.
那么,这两个分支究竟有什么区别呢?这个本地代码走的代码分支,有一段很重要的逻辑.
他这里会根据资源文件进行排序,那么到底根据什么规则排序.
此时豁然开朗.为什么本地一直没有重现?因为本地跑的时候,他走的代码逻辑已经把资源文件默认按照文件名排序了,导致了这个UserMapper.xml一直在UserPersonalMapper.xml之前加载.
其实这种两个mapper引用的做法我认为是非常不规范的.因为资源文件打进jar的文件排序是非常不可控的,
# 一步步放弃mybatis的xml
# foreach用法:List、Array、Map三种类型遍历
# foreach元素的属性
- collection: 需做foreach(遍历)的对象,作为入参时,list、array对象时,collection属性值分别默认用"list"、"array"代替,Map对象没有默认的属性值。但是,在作为入参时可以使用@Param(“keyName”)注解来设置自定义collection属性值,设置keyName后,list、array会失效;
- item: 集合元素迭代时的别名称,该参数为必选项;
- index: 在list、array中,
index为元素的序号索引。但是在Map中,index为遍历元素的key值,该参数为可选项; - open: 遍历集合时的开始符号,通常与close=")"搭配使用。使用场景IN(),values()时,该参数为可选项;
- separator: 元素之间的分隔符,类比在IN()的时候,separator=",",最终所有遍历的元素将会以设定的(,)逗号符号隔开,该参数为可选项;
- close: 遍历集合时的结束符号,通常与open="("搭配使用,该参数为可选项;
# foreach时,collection属性值的三种情况
- 如果传入的参数类型为List时,collection的默认属性值为list(即
Map<list, value>,否则就需要自行包装成Map),同样可以使用@Param注解自定义keyName; - 如果传入的参数类型为array时,collection的默认属性值为array,同样可以使用@Param注解自定义keyName;
- 如果传入的参数类型为Map时,collection的属性值可为三种情况:(1.遍历map.keys;2.遍历map.values;3.遍历map.entrySet()),稍后会在代码中示例;
# collection属性值类型为List
建议做
if test="xxxx !=null and xxxx.size()>0"的校验,比较严谨。array为.length();
List<UserList> getUserInfo(@Param("userName") List<String> userName);
<select id="getUserInfo" resultType="com.test.UserList">
SELECT
*
FROM user_info
where
<if test="userName!= null and userName.size() >0">
USERNAME IN
<foreach collection="userName" item="value" separator="," open="(" close=")">
#{value}
</foreach>
</if>
</select>
2
3
4
5
6
7
8
9
10
11
12
- 以下为任由mybatis自行处理list参数
List<UserList> getUserInfo(List<String> userName);
<select id="getUserInfo" resultType="com.test.UserList" parameterType="list">
SELECT
*
FROM user_info
where
<if test="userName!= null and userName.size() >0">
USERNAME IN
<foreach collection="list" item="value" separator="," open="(" close=")">
#{value}
</foreach>
</if>
</select>
2
3
4
5
6
7
8
9
10
11
12
# collection属性值类型为Array
建议做if test="xxxx !=null and xxxx.length()>0"的校验,比较严谨
List<UserList> getUserInfo(@Param("userName") String[] userName);
<select id="getUserInfo" resultType="com.test.UserList">
SELECT
*
FROM user_info
where
<if test="userName!= null and userName.length() >0">
USERNAME IN
<foreach collection="userName" item="value" separator="," open="(" close=")">
#{value}
</foreach>
</if>
</select>
2
3
4
5
6
7
8
9
10
11
12
# collection属性值类型为Map
建议做 if test="xxxx !=null and xxxx.size()>0"的校验,比较严谨
Map<String, String> patientMap = userList.stream().filter(item -> StringUtils.hasText(item.getUserName()) &&
StringUtils.hasText(item.getAge())).collect(Collectors.toMap(UserList::getUserName, UserList::getAge));
List<UserList> getUserInfo(@Param("user") Map<String,String> user);
2
3
4
- 第一种:获取Map的键值对,
多字段组合条件情况下,一定要注意书写格式:括号()
eg: SELECT * FROM user_info WHERE (USERNAME,AGE) IN (('张三','26'),('李四','58'),('王五','27'),......);
<select id="getUserInfo" resultType="com.test.UserList">
SELECT
*
FROM user_info
where
<if test="user!= null and user.size() >0">
(USERNAME,AGE) IN
<foreach collection="user.entrySet()" item="value" index="key" separator="," open="(" close=")">
(#{key},#{value})
</foreach>
</if>
</select>
2
3
4
5
6
7
8
9
10
11
12
- 第二种:参数Map类型,只需要获取key值或者value值
<select id="getUserInfo" resultType="com.test.UserList">
SELECT
*
FROM user_info
where
<if test="user!= null and user.size() >0">
(USERNAME) IN
<foreach collection="user.keys" item="key" separator="," open="(" close=")">
#{key}
</foreach>
</if>
</select>
2
3
4
5
6
7
8
9
10
11
12
<select id="getUserInfo" resultType="com.test.UserList">
SELECT
*
FROM user_info
where
<if test="user!= null and user.size() >0">
(USERNAME) IN
<foreach collection="user.values" item="value" separator="," open="(" close=")">
#{key}
</foreach>
</if>
</select>
2
3
4
5
6
7
8
9
10
11
12
# 参数为map查询条件在json字符串里
<if test="@com.fourfaith.base.mybatis.Ognl@isNotEmpty(params.searchMap)">
<foreach collection="params.searchMap.entrySet()" item="value" index="key" separator=" ">
<if test="@com.fourfaith.base.mybatis.Ognl@isNotEmpty(value)">
and json_unquote(json_extract(sce.data,'$."${key}"')) = #{value}
</if>
</foreach>
</if>
2
3
4
5
6
7
# 一个方法实现插入或更新,必须有主键
<insert id="updateBatch" parameterType="java.util.List">
insert into standard_relation(id,relation_type, standard_from_uuid,
standard_to_uuid, relation_score, stat,
last_process_id, is_deleted, gmt_created,
gmt_modified,relation_desc)VALUES
<foreach collection="list" item="item" index="index" separator=",">
(#{item.id,jdbcType=BIGINT},#{item.relationType,jdbcType=VARCHAR}, #{item.standardFromUuid,jdbcType=VARCHAR},
#{item.standardToUuid,jdbcType=VARCHAR}, #{item.relationScore,jdbcType=DECIMAL}, #{item.stat,jdbcType=TINYINT},
#{item.lastProcessId,jdbcType=BIGINT}, #{item.isDeleted,jdbcType=TINYINT}, #{item.gmtCreated,jdbcType=TIMESTAMP},
#{item.gmtModified,jdbcType=TIMESTAMP},#{item.relationDesc,jdbcType=VARCHAR})
</foreach>
ON DUPLICATE KEY UPDATE
id=VALUES(id),relation_type = VALUES(relation_type),standard_from_uuid = VALUES(standard_from_uuid),standard_to_uuid = VALUES(standard_to_uuid),
relation_score = VALUES(relation_score),stat = VALUES(stat),last_process_id = VALUES(last_process_id),
is_deleted = VALUES(is_deleted),gmt_created = VALUES(gmt_created),
gmt_modified = VALUES(gmt_modified),relation_desc = VALUES(relation_desc)
</insert>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# OGNL
Object-Graph Navigation Language(对象视图导航语言)
# 直接调用java中的方法
rate = '${@com.ht.port.util.TransferUtil@findRate(item)}'
其中findRate必须是公共静态方法
# if标签test上使用
<if test='@org.apache.commons.lang3.StringUtils@isNotBlank(paramName)'>t.name=#{paramName}</if>
<if test='@com.ht.constant.LcdConstant@ONE == 变量名'></if>
2
3
# 直接调用java中静态变量
'
${@全路径名@常量名}'
t.name='${@com.ht.common.Constant@DEFAULT_NAME}'
# 使用枚举值
- '${@全路径名@枚举值.
get属性()}' - '${@全路径名@枚举值}' -- 拿到枚举值的name
t.name=${@com.ht.common.HtEunm@ONE.getCode()}
t.name='${@com.ht.common.HtEunm@ONE}'
2
# bind标签中引用
<bind name='rateValue' value='@com.ht.port.util.TransferUtil@findRate(item)' />
但是请注意,bind标签有个坑,因为它是把value的值绑定到finalItem中,即finalItem相当于一个静态变量,如果在循环中就会出问题,如下,就会发现rate绑定的参数是同一个值
<foreach item='item' index='index' collection='keyWord.split(",")' open='AND (' separator='AND' close=')'>
(name LIKE binary CONCAT('%',trim(#{item}),'%'))
<bind name='rateValue' value='@com.ht.port.util.TransferUtil@findRate(item)'/>
OR rate = #{rateValue}
</foreach>
2
3
4
5
# 使用内部类
外部类与内部类采用美元符号【
$】隔开(package.OuterClass$InnerClass)
t.LCS_CD in
${@com.ht.common.enums.IAbnmlAccEnum$AbnmalLcsCdENum@findCheckedLcsCds(unCd)}
2
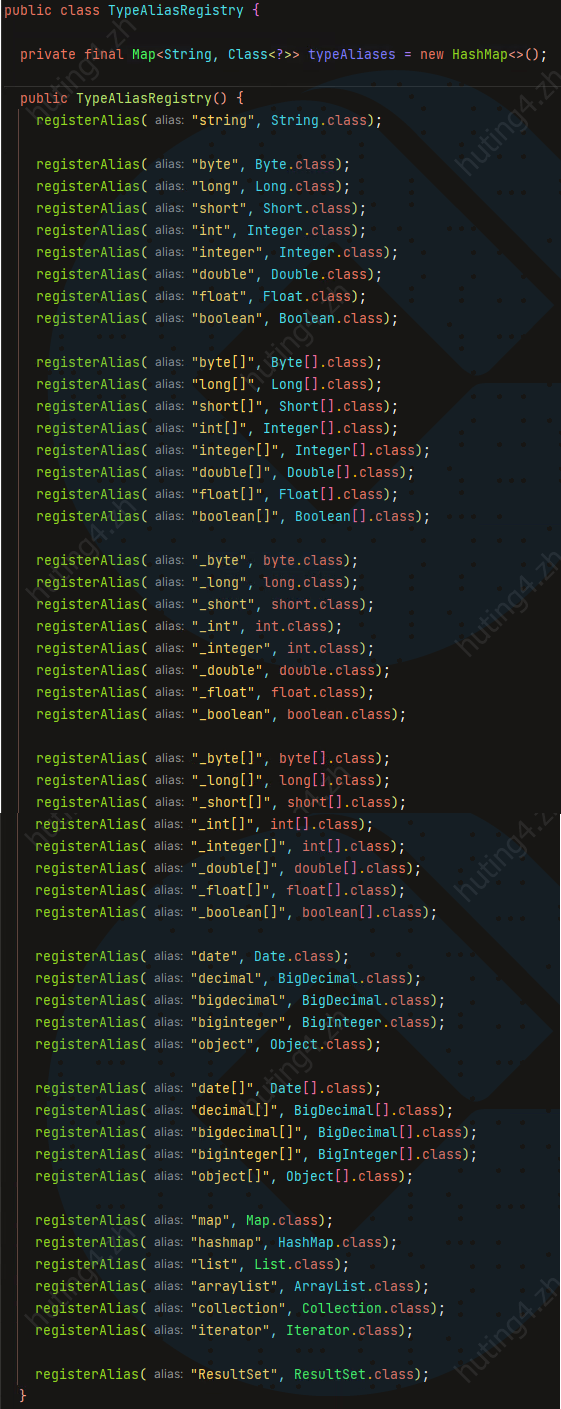
# 类型别名
别名不区分大小写
# 内置类型别名
| Alias | Mapped Type |
|---|---|
| _byte | byte |
| _long | long |
| _short | short |
| _int | int |
| _integer | int |
| _double | double |
| _float | float |
| _boolean | boolean |
| string | String |
| byte | Byte |
| long | Long |
| short | Short |
| int | Integer |
| integer | Integer |
| double | Double |
| float | Float |
| boolean | Boolean |
| date | Date |
| decimal | BigDecimal |
| bigdecimal | Bigdecimal |
| object | Object |
| map | Map |
| hashmap | HashMap |
| list | List |
| arraylist | ArrayList |
| collection | Collection |
| iterator | Iterator |
# 自定义别名
# 1、配置指定别名
<typeAliases>
<typeAlias type='com.ht.pojo.Dept' alias='dept1'/>
</typeAliases>
2
3
# 2、指定包下取别名(类名即别名)
<typeAliases>
<typeAlias type='com.ht.pojo.Dept' alias='dept1'/>
<package name='com.ht.pojo' />
</typeAliases>
2
3
4
(以上,dept1与Dept都可以作为别名)
# 3、注解取别名
@Alias放在类上,并取名,如:@Alias('HtDept') 注意:此时配置指定别名仍可使用,但是指定包名下取别名则不可用
# trim
一般用于去除sql语句里多余的'and'关键字、逗号(',')、或者给sql语句拼接'where'、'set'以及'values('等前缀或者添加')'
# prefix
给sql语句添加前缀
# suffix
给sql语句添加后缀
# prefixOverrides
去除sql语句前面的关键字或者字符,该关键字或者字符由prefixOverrides属性指定,假设prefixOverrides='AND',当sql语句的开头位AND时,trim标签则会删除该AND
# suffixOverrides
同上,去除sql语句末尾的关键字或者字符
# 其他实现动态sql的元素
if、choose(when,otherwise)、foreach
# where
智能优化where条件,自动忽略首部的and、or之类的关键字
# set
如果set包含内容为空时,会报错。
# 进阶
# 如何获取新插入数据的ID信息
<insert id="addJobTpl" parameterType="com.ccb.nrmm.data.po.JobTplPo" useGeneratedKeys="true" keyProperty="tplId">
insert into rwa_tpl_info(tpl_nm,tpl_dsc,ceate_id,create_time,update_time)
values (#{tplNm},#{tplDsc},#{createId},sysdate(),sysdate())
</insert>
2
3
4
关键信息useGeneratedKeys和keyProperty
经过上述改造后的插入语句会在入库后将自增长的id信息写入对象里指定的id属性中,上述例子则会写到tplId中
<insert id="addJobTpl" parameterType="com.ccb.nrmm.data.po.JobTplPo">
insert into rwa_tpl_info(tpl_nm,tpl_dsc,ceate_id,create_time,update_time)
values (#{tplNm},#{tplDsc},#{createId},sysdate(),sysdate())
<selectKey>
select @@identity
</selectKey>
</insert>
<!-- 或者 -->
<insert id="addJobTpl" parameterType="com.ccb.nrmm.data.po.JobTplPo">
insert into rwa_tpl_info(tpl_nm,tpl_dsc,ceate_id,create_time,update_time)
values (#{tplNm},#{tplDsc},#{createId},sysdate(),sysdate())
<selectKey>
select LAST_INSERT_ID()
</selectKey>
</insert>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
上述方式,不保险,无法保证数据里最新插入的id是当前表的,容易错乱,不建议使用
# xml里批量更新数据
批量插入和批量更新的原理:
把多条sql拼接为一条。
材料准备:测试表 test1
-- 测试表 test1
CREATE TABLE `test1` (
`id` int(14) NOT NULL,
`name` varchar(50) DEFAULT NULL,
`remark1` varchar(50) DEFAULT NULL,
`remark2` varchar(50) DEFAULT NULL,
`remark3` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
2
3
4
5
6
7
8
9
# 一、批量插入
例如:要插入3条数据,那么非批量的插入数据,执行sql分别为:
insert into test1(id,name,remark1,remark2,remark3)
values(1,'sb','rmk11','rmk12','rmk13');
insert into test1(id,name,remark1,remark2,remark3)
values(2,'sb','rmk21','rmk22','rmk23');
insert into test1(id,name,remark1,remark2,remark3)
values(3,'sb','rmk33','rmk32','rmk33');
2
3
4
5
6
7
8
我们可以将以上的3条sql转变为1条sql:
insert into test1(id,name,remark1,remark2,remark3)
VALUES
(1,'sb','rmk11','rmk12','rmk13'),
(2,'sb','rmk21','rmk22','rmk23'),
(3,'sb','rmk33','rmk32','rmk33');
2
3
4
5
这样就只需要连接一次数据库,并且执行一条sql就可以插入多条数据了。
当然我们如果使用了mybatis,那么在插入多条数据的时候,不需要自己拼接sql,mybatis可以帮我们拼接。
TestBatchService 中的方法只需要把,需要插入的数据放入一个集合List中,然后直接调用mapper方法。
public void testInsertBatch() {
List<Test1> list = new ArrayList<>();
for (int i=0;i<10000;i++){
//拼装测试数据
Test1 test1 = new Test1();
test1.setId(i);
test1.setName("sb"+i);
test1.setRemark1("remark1_"+i);
test1.setRemark2("remark2_"+i);
test1.setRemark3("remark3_"+i);
list.add(test1);
}
testBatchMapper.insertBatch(list);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
在使用mybatis时,mapper我们可以这么配置,例如:在TestBatchMapper.xml中
<!-- 批量插入 -->
<insert id="insertBatch">
insert into test1
(id,name,remark1,remark2,remark3)
values
<foreach collection ="list" item="tt" separator =",">
(#{tt.id}, #{tt.name}, #{tt.remark1}, #{tt.remark2}, #{tt.remark3})
</foreach>
</insert>
2
3
4
5
6
7
8
9
这样mybatis就帮我们把list的数据一个个拿出来拼接成一条sql,最后执行。性能可以说是非常高效,本机测试10000条数据的插入在2秒内完成!
# 二、批量更新
非批量更新的做法,在循环体中逐条更新数据。
public void testUpdate() {
long startTime = System.currentTimeMillis();
System.out.println("开始时间为:"+startTime);
for (int i=0;i<10000;i++){
Test1 test1 = new Test1();
test1.setId(i);
test1.setName("update_sb"+i);
test1.setRemark1("update_remark1_"+i);
test1.setRemark2("update_remark2_"+i);
test1.setRemark3("update_remark3_"+i);
this.update(test1);
}
long endTime = System.currentTimeMillis();
System.out.println("结束时间为:"+endTime);
long totalTime = endTime - startTime ;
System.out.println("总耗时:"+totalTime);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
批量更新的方法把数据放到一个集合list中,然后一次更新:
public void testUpdateBatch() {
List<Test1> list = new ArrayList<>();
long startTime = System.currentTimeMillis();
System.out.println("开始时间为:"+startTime);
for (int i=0;i<10000;i++){
Test1 test1 = new Test1();
test1.setId(i);
test1.setName("batch_update_sb"+i);
test1.setRemark1("batch_update_remark1_"+i);
test1.setRemark2("batch_update_remark2_"+i);
test1.setRemark3("batch_update_remark3_"+i);
list.add(test1);
}
this.updateBatch(list);
long endTime = System.currentTimeMillis();
System.out.println("结束时间为:"+endTime);
long totalTime = endTime - startTime ;
System.out.println("总耗时:"+totalTime);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
TestBatchMapper.xml的配置为:
<!-- 高效的批量更新 本地测试10000条数据 -->
<update id="updateBatch" parameterType="java.util.List">
update test1
set name=
<foreach collection="list" item="item" index="index"
separator=" " open="case ID" close="end">
when #{item.id} then #{item.name}
</foreach>,
remark1 =
<foreach collection="list" item="item" index="index"
separator=" " open="case ID" close="end">
when #{item.id} then #{item.remark1}
</foreach>,
remark2 =
<foreach collection="list" item="item" index="index"
separator=" " open="case ID" close="end">
when #{item.id} then #{item.remark2}
</foreach>,
remark3 =
<foreach collection="list" item="item" index="index"
separator=" " open="case ID" close="end">
when #{item.id} then #{item.remark3}
</foreach>
where id in
<foreach collection="list" index="index" item="item"
separator="," open="(" close=")">
#{item.id,jdbcType=BIGINT}
</foreach>
</update>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
批量更新利用了mysql的 cas ... when ... then 的原理,把sql拼接为一条,最后执行。本机测试结果:使用普通更新10000条数据需要 100多秒,使用批量更新10000条数据只需要8秒,批量性能还是挺高效的。
# 三、mysql的 case ... when ... then 的简单
既然上面提到了mysql的case ... when ... then 的使用,那么我们简单分析一下其用法,
例如我们要更新3条数据到test1表中:
原数据
id name remark1
1 sb muji
2 sb muji
3 sb muji
2
3
4
需要更新成以下数据
id name remark1
1 sb1 remarksb1
2 sb22 remarksb2
3 sb333 remarksb3
2
3
4
那么我们可以把这3条数据拼成以下sql:
update test1
set
name =
case
when id=1 then 'sb1'
when id=2 then 'sb22'
when id=3 then 'sb333'
end
,
remark1 =
case
when id=1 then 'remarksb1'
when id=2 then 'remarksb2'
when id=3 then 'remarksb3'
end
where id in(1,2,3);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
这样就可以使用一条数据,更新多条数据了,以上mybatis的批量更新就是利用了这个原理。
# 四、使用批量插入和批量更新的缺点
使用批量处理性能很高,但是存在以下缺点:
- 1、在批量处理过程中,使用了事务如果出现其中的某些数据执行出错,那么会全部回滚,并且无法定位到错误的数据。
- 2、因为是将多条sql拼接为一条所以数据量大会导致sql的数据很长,超过设置的长度会报错。
基于缺点1,
我们可以将数据按批次批量处理,例如 把10000条拆成每次1000条按10次完成,这样就可以平衡性能和数据的出错时候定位数据范围的问题。 基于缺点2:使用 查看mysql的 sql的最大长度:
show variables like '%max_allowed_packet%';
当然我们可以在mysql的配置文件(my.ini)中的 max_allowed_packet = 60M 修改此项,来解决问题。
本机性能测试结果
| 数据量(条) | insert | insertBatch | update | updateBatch |
|---|---|---|---|---|
| 1000 条 | 15765 ms | 166 ms | 7268 ms | 246 ms |
| 5000 条 | 65906 ms | 973 ms | 12201 ms | 2587 ms |
| 10000 条 | 127057 ms | 1283 ms | 109010 ms | 8815 ms |