# MongoDB
| Spring整合mongoDb | MongoDB 全方位知识图谱; |
|---|---|
| 索引的重要性 | 执行计划 |
NoSQL简介
NoSQL(NoSQL = Not Only SQL ),意即"不仅仅是SQL"。
在现代的计算系统上每天网络上都会产生庞大的数据量。
这些数据有很大一部分是由关系数据库管理系统(RDBMS)来处理。 1970年 E.F.Codd's提出的关系模型的论文 "A relational model of data for large shared data banks",这使得数据建模和应用程序编程更加简单。
通过应用实践证明,关系模型是非常适合于客户服务器编程,远远超出预期的利益,今天它是结构化数据存储在网络和商务应用的主导技术。
NoSQL 是一项全新的数据库革命性运动,早期就有人提出,发展至2009年趋势越发高涨。NoSQL的拥护者们提倡运用非关系型的数据存储,相对于铺天盖地的关系型数据库运用,这一概念无疑是一种全新的思维的注入。
NoSQL,指的是非关系型的数据库。NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。
NoSQL用于超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
# 关系型数据库遵循ACID规则
事务在英文中是transaction,和现实世界中的交易很类似,它有如下四个特性:
- 1、A (Atomicity) 原子性
原子性很容易理解,也就是说事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚。 比如银行转账,从A账户转100元至B账户,分为两个步骤:1)从A账户取100元;2)存入100元至B账户。这两步要么一起完成,要么一起不完成,如果只完成第一步,第二步失败,钱会莫名其妙少了100元。
- 2、C (Consistency) 一致性
一致性也比较容易理解,也就是说数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。 例如现有完整性约束a+b=10,如果一个事务改变了a,那么必须得改变b,使得事务结束后依然满足a+b=10,否则事务失败。
- 3、I (Isolation) 独立性
所谓的独立性是指并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。 比如现在有个交易是从A账户转100元至B账户,在这个交易还未完成的情况下,如果此时B查询自己的账户,是看不到新增加的100元的。
- 4、D (Durability) 持久性
持久性是指一旦事务提交后,它所做的修改将会永久的保存在数据库上,即使出现宕机也不会丢失。
# 分布式系统
分布式系统(distributed system)由多台计算机和通信的软件组件通过计算机网络连接(本地网络或广域网)组成。
分布式系统是建立在网络之上的软件系统。正是因为软件的特性,所以分布式系统具有高度的内聚性和透明性。
因此,网络和分布式系统之间的区别更多的在于高层软件(特别是操作系统),而不是硬件。
分布式系统可以应用在不同的平台上如:Pc、工作站、局域网和广域网上等。
# 为什么使用NoSQL
今天我们可以通过第三方平台(如:Google,Facebook等)可以很容易的访问和抓取数据。用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍的增加。我们如果要对这些用户数据进行挖掘,那SQL数据库已经不适合这些应用了, NoSQL 数据库的发展却能很好的处理这些大的数据。
# RDBMS vs NoSQL
- RDBMS
- 高度组织化结构化数据
- 结构化查询语言(SQL) (SQL)
- 数据和关系都存储在单独的表中。
- 数据操纵语言,数据定义语言
- 严格的一致性
- 基础事务
- NoSQL
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式
- - 值对存储,列存储,文档存储,图形数据库
- 最终一致性,而非ACID属性
- 非结构化和不可预知的数据
- CAP定理
- 高性能,高可用性和可伸缩性
# CAP定理(CAP_theorem)
在计算机科学中, CAP定理(CAP theorem), 又被称作 布鲁尔定理(Brewer's theorem), 它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency) (所有节点在同一时间具有相同的数据)
- 可用性(Availability) (保证每个请求不管成功或者失败都有响应)
- 分隔容忍(Partition tolerance) (系统中任意信息的丢失或失败不会影响系统的继续运作)
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类:
- CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
- CP - 满足一致性,分区容忍性的系统,通常性能不是特别高。
- AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
# NoSQL的优点/缺点
- 优点:
- 高可扩展性
- 分布式计算
- 低成本
- 架构的灵活性,半结构化数据
- 没有复杂的关系
- 缺点:
- 没有标准化
- 有限的查询功能(到目前为止)
- 最终一致是不直观的程序
# BASE
BASE:Basically Available, Soft-state, Eventually Consistent。 由 Eric Brewer 定义。
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
BASE是NoSQL数据库通常对可用性及一致性的弱要求原则:
- Basically Availble --基本可用
- Soft-state --软状态/柔性事务。 "Soft state" 可以理解为"无连接"的, 而 "Hard state" 是"面向连接"的
- Eventual Consistency -- 最终一致性, 也是是 ACID 的最终目的。
# ACID vs BASE
| ACID | BASE |
|---|---|
| 原子性(Atomicity) | 基本可用(Basically Available) |
| 一致性(Consistency) | 软状态/柔性事务(Soft state) |
| 隔离性(Isolation) | 最终一致性 (Eventual consistency) |
| 持久性 (Durable) |
# NoSQL 数据库分类
| 类型 | 部分代表 | 特点 |
|---|---|---|
| 列存储 | Hbase、Cassandra、Hypertable | 顾名思义,是按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有非常大的IO优势。 |
| 文档存储 | MongoDB、CouchDB | 文档存储一般用类似json的格式存储,存储的内容是文档型的。这样也就有机会对某些字段建立索引,实现关系数据库的某些功能。 |
| key-value存储 | Tokyo Cabinet / Tyrant、Berkeley DB、MemcacheDB、Redis | 可以通过key快速查询到其value。一般来说,存储不管value的格式,照单全收。(Redis包含了其他功能) |
| 图存储 | Neo4J、FlockDB | 图形关系的最佳存储。使用传统关系数据库来解决的话性能低下,而且设计使用不方便。 |
| 对象存储 | db4o、Versant | 通过类似面向对象语言的语法操作数据库,通过对象的方式存取数据。 |
| xml数据库 | Berkeley DB XML、BaseX | 高效的存储XML数据,并支持XML的内部查询语法,比如XQuery,Xpath。 |
# 1、什么是MongoDB
MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。
在高负载的情况下,添加更多的节点,可以保证服务器性能。
MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
# 2、主要特点
MongoDB 是一个面向文档存储的数据库,操作起来比较简单和容易。
你可以在MongoDB记录中设置任何属性的索引 (如:FirstName="Sameer",Address="8 Gandhi Road")来实现更快的排序。
你可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性。
如果负载的增加(需要更多的存储空间和更强的处理能力) ,它可以分布在计算机网络中的其他节点上这就是所谓的分片。
- Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
- MongoDb 使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。
- Mongodb中的Map/reduce主要是用来对数据进行批量处理和聚合操作。
- Map和Reduce。Map函数调用emit(key,value)遍历集合中所有的记录,将key与value传给Reduce函数进行处理。
- Map函数和Reduce函数是使用Javascript编写的,并可以通过db.runCommand或mapreduce命令来执行MapReduce操作。
- GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件。
- MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
- MongoDB支持各种编程语言:RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
- MongoDB安装简单。
# 安装
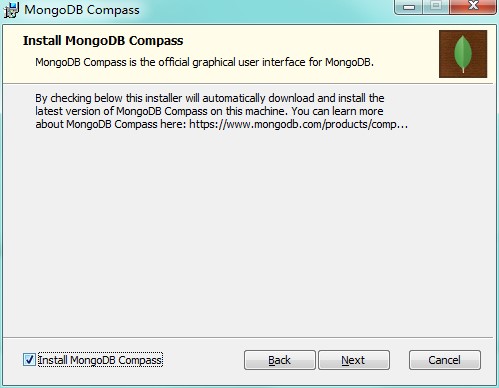
不要勾选install mongodb compass
# 3、MongoDB概念解析
不管我们学习什么数据库都应该学习其中的基础概念,在mongodb中基本的概念是文档、集合、数据库,下面我们挨个介绍。
mongodb和redis一样是一种NoSQL存储介质,存储读取快,但实质上它又是一种介于关系型数据库(如mysql,数据存在磁盘中)和非关系型数据库(如redis,数据存在内存中)的介质,它数据存在磁盘,但读取又借助内存机制映射进行,所以集成了关系型和非关系型的各自优点。它的设计是基于分布式储存的,可用集群部署来分压。
下表将帮助您更容易理解Mongo中的一些概念:
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table | joins | 表连接,MongoDB不支持 |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
# 4、数据库
一个mongodb中可以建立多个数据库。
MongoDB的默认数据库为"db",该数据库存储在data目录中。
MongoDB的单个实例可以容纳多个独立的数据库,每一个都有自己的集合和权限,不同的数据库也放置在不同的文件中。
"show dbs" 命令可以显示所有数据的列表。
执行 "db" 命令可以显示当前数据库对象或集合。
运行"use"命令,可以连接到一个指定的数据库。
数据库也通过名字来标识。数据库名可以是满足以下条件的任意UTF-8字符串。
不能是空字符串
("")。
不得含有' '(空格)、.、$、/、\和\0 (空字符)。
应全部小写。
最多64字节。
创建数据库用户:
db.createUser({user:'ht',pwd:'clm',roles:[{role:'dbOwner',db:'httest'}]})
有一些数据库名是保留的,可以直接访问这些有特殊作用的数据库。
admin:从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
# 文档(Document)
文档是一组键值(key-value)对(即 BSON)。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。
一个简单的文档例子如下:
{"site":"www.runoob.com", "name":"菜鸟教程"}
下表列出了 RDBMS 与 MongoDB 对应的术语:
| RDBMS | MongoDB |
|---|---|
| 数据库 | 数据库 |
| 表格 | 集合 |
| 行 | 文档 |
| 列 | 字段 |
| 表联合 | 嵌入文档 |
| 主键 | 主键 (MongoDB 提供了 key 为 _id ) |
# 需要注意的是
- 文档中的键/值对是有序的。
- 文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
- MongoDB区分类型和大小写。
- MongoDB的文档不能有重复的键。
- 文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
# 文档键命名规范
- 键不能含有
\0 (空字符)。这个字符用来表示键的结尾。.和$有特别的意义,只有在特定环境下才能使用。以下划线"_"开头的键是保留的(不是严格要求的)。
# 集合
集合就是 MongoDB 文档组,类似于 RDBMS (关系数据库管理系统:Relational Database Management System)中的表格。
集合存在于数据库中,集合没有固定的结构,这意味着你在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性。
比如,我们可以将以下不同数据结构的文档插入到集合中:
{"site":"www.baidu.com"}
{"site":"www.google.com","name":"Google"}
{"site":"www.runoob.com","name":"菜鸟教程","num":5}
2
3
当第一个文档插入时,集合就会被创建。
# 合法的集合名
- 集合名不能是空字符串
""。- 集合名不能含有
\0字符(空字符),这个字符表示集合名的结尾。- 集合名不能以
"system."开头,这是为系统集合保留的前缀。- 用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现$。
# MongoDB创建数据库
# 语法-创建数据库
MongoDB 创建数据库的语法格式如下:
use DATABASE_NAME
如果数据库不存在,则创建数据库,否则切换到指定数据库。
# 实例-创建数据库
以下实例我们创建了数据库 httest:
> use httest
switched to db httest
> db
httest
>
2
3
4
5
如果你想查看所有数据库,可以使用 show dbs 命令:
> show dbs
admin 0.000GB
local 0.000GB
>
2
3
4
可以看到,我们刚创建的数据库 httest 并不在数据库的列表中, 要显示它,我们需要向 httest 数据库插入一些数据。
> db.httest.insert({"name":"htring"})
WriteResult({ "nInserted" : 1 })
> show dbs
local 0.078GB
httest 0.078GB
test 0.078GB
>
2
3
4
5
6
7
MongoDB 中默认的数据库为 test,如果你没有创建新的数据库,集合将存放在 test 数据库中。
注意: 在 MongoDB 中,集合只有在内容插入后才会创建! 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
# MongoDB删除数据库
# 语法-删除数据库
MongoDB 删除数据库的语法格式如下:
db.dropDatabase()
删除当前数据库,默认为 test,你可以使用 db 命令查看当前数据库名。
# 实例-删除数据库
以下实例我们删除了数据库 runoob。
首先,查看所有数据库:
> show dbs
local 0.078GB
runoob 0.078GB
test 0.078GB
2
3
4
接下来我们切换到数据库 runoob:
> use runoob
switched to db runoob
>
2
3
执行删除命令:
> db.dropDatabase()
{ "dropped" : "runoob", "ok" : 1 }
2
最后,我们再通过 show dbs 命令数据库是否删除成功:
> show dbs
local 0.078GB
test 0.078GB
>
2
3
4
# MongoDB删除集合
集合删除语法格式如下:
db.collection.drop()
以下实例删除了 runoob 数据库中的集合 site:
> use runoob
switched to db runoob
> show tables
site
> db.site.drop()
true
> show tables
>
2
3
4
5
6
7
8
# MongoDB创建集合
本章节我们为大家介绍如何使用 MongoDB 来创建集合。
MongoDB 中使用 createCollection() 方法来创建集合。
语法格式:
db.createCollection(name, options)
参数说明:
name: 要创建的集合名称options: 可选参数, 指定有关内存大小及索引的选项
options 可以是如下参数:
| 字段 | 类型 | 描述 |
|---|---|---|
| capped | 布尔 | (可选)如果为 true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。当该值为 true 时,必须指定 size 参数。 |
| autoIndexId | 布尔 | (可选)如为 true,自动在 _id 字段创建索引。默认为 false。 |
| size | 数值 | (可选)为固定集合指定一个最大值(以字节计)。如果 capped 为 true,也需要指定该字段。 |
| max | 数值 | (可选)指定固定集合中包含文档的最大数量。 |
在插入文档时,MongoDB 首先检查固定集合的 size 字段,然后检查 max 字段。
# 实例-MongoDB创建集合
在 test 数据库中创建 runoob 集合:
> use test
switched to db test
> db.createCollection("runoob")
{ "ok" : 1 }
>
2
3
4
5
如果要查看已有集合,可以使用 show collections 命令:
> show collections
runoob
system.indexes
2
3
下面是带有几个关键参数的 createCollection() 的用法:
- 创建固定集合 mycol,整个集合空间大小 6142800 KB, 文档最大个数为 10000 个。
> db.createCollection("mycol", { capped : true, autoIndexId : true, size :
6142800, max : 10000 } )
{ "ok" : 1 }
>
2
3
4
在 MongoDB 中,你不需要创建集合。当你插入一些文档时,MongoDB 会自动创建集合。
> db.mycol2.insert({"name" : "菜鸟教程"})
> show collections
mycol2
...
2
3
4
# 基本操作
# 服务端启动步骤
在要启动的目录下新建一个目录(如:data)
mkdir data
命令行中输入(--dbpath参数指定数据库路径)
mongod --dbpath='./data'
如果出现waiting for connections on port 27017就表示启动成功。
mongod启动命令mongod参数说明
| 选项 | 含义 |
|---|---|
--port | 指定服务端口号,默认端口27017 |
--logpath | 指定MongoDB日志文件,注意是指定文件不是目录 |
--logappend | 使用追加的方式写日志 |
--dbpath | 指定数据库路径 |
--directoryperdb | 设置每个数据库将被保存在一个单独的目录 |
# 客户端启动
命令行输入
mongo
也可以设置host
mongo --host 127.0.0.1
# MongoDB基本概念
数据库MongoDB的单个实例可以容纳多个独立的数据库,比如一个学生管理系统就可以对应一个数据库实例。集合数据库是由集合组成的,一个集合用来表示一个实体,如学生集合。文档集合是由文档组成的,一个文档表示一条记录,比如一位同学张三就是一个文档
# 数据库操作
show dbs查看所有数据库use ht切换数据库
如果此数据库存在,则切换到此数据库下,如果此数据库还不存在也可以切过来
注: 我们刚创建的数据库ht如果不在列表内,要显示它,我们需要向ht数据库插入一些数据
db或者db.getName()显示当前数据库名称db.dropDatabase()删除数据库(当前使用的数据库)
# 集合操作
db.ht.help()查看所有帮助show collections查看数据库下的集合db.createCollection('htCol'),db.htCol.insert({name: 'htring', age: 8})
# 文档操作
# 插入文档
insert,db.htCol.insert({name: 'htring', age: 8})
每当插入一条新文档的时候mongodb会自动为此文档生成一个
_id属性,_id一定是唯一的,用来唯一标识一个文档_id也可以直接指定,但如果数据库中此集合下已经有此_id的话插入会失败。
save
--insert
db.grade1.insert({_id: '1',name: 'Han Meimei', age: 8})// WriteResult({ "nInserted" : 1 })
--存在{_id:1},则更新 _id为1的document
db.grade1.save({_id: '1',name: 'Han Meimei', age: 9})// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
--不存在{_id:2},则插入一条新文档
db.grade1.save({_id: '2',name: 'Han Meimei', age: 9})// WriteResult({ "nMatched" : 0, "nUpserted" : 1, "nModified" : 0, "_id" : "2" })
2
3
4
5
6
7
8
执行脚本插入
mongo exc_js/1.js
> load exc_js/1.js
2
# 更新文档
db.collection.update(
<query>,
<updateObj>,
{
upsert: <boolean>,
multi: <boolean>
}
)
2
3
4
5
6
7
8
query 查询条件,指定要更新符合哪些条件的文档
update 更新后的对象或指定一些更新的操作符
$set直接指定更新后的值
$inc在原基础上累加
upsert 可选,这个参数的意思是,如果不存在符合条件的记录时是否插入updateObj. 默认是false,不插入。
multi 可选,mongodb 默认只更新找到的第一条记录,如果这个参数为true,就更新所有符合条件的记录。
# $inc
{ $inc: { <field1>: <amount1>, <field2>: <amount2>, ... } }
在原基础上累加(increment)
// 给 {name: 'Tom'} 的文档的age累加 10
db.htCol.update({name: 'htring'}, {$inc: {age:10}})
2
# $push
{ $push: { <field1>: <value1>, ... } }
向数组中添加元素
db.grade1.update({name:'Tom'}, {$push: {'hobby':'reading'} })
// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
// { "_id" : ObjectId("5addbfbb163098017a6a72ed"), "name" : "Tom", "hobby" : [ "reading" ] }
// 不会覆盖已有的
db.grade1.update({name:'Tom'}, {$push: {'hobby':'reading'} })
// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
// { "_id" : ObjectId("5addbfbb163098017a6a72ed"), "name" : "Tom", "hobby" : [ "reading", "reading" ] }
2
3
4
5
6
7
8
# $addToSet
{ $addToSet: { <field1>: <value1>, ... } }
给数组添加或者设置一个值,
有 - do nothing, 没有 - 添加
// /第一次没有 huge
db.grade1.update({_id:3}, {$addToSet: {friends:'huge'}})
// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
// 第二次 有 huge
db.grade1.update({_id:3}, {$addToSet: {friends:'huge'}})
// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 0 })
2
3
4
5
6
7
8
# $pop
{ $pop: { <field>: <-1 | 1>, ... } }
删除数组的第一个或者最后一个元素。
传入1删除最后一个元素
传入-1删除第一个元素
db.grade1.update({_id:3}, {$pop:{friends: 1}})
// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
db.grade1.update({_id:3}, {$pop:{friends: -1}})
// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
2
3
4
5
# $each
- Use with the
$addToSetoperator to add multiple values to an array if the values do not exist
{ $addToSet: { <field>: { $each: [ <value1>, <value2> ... ] } } }
db.grade1.update({_id:3}, {$addToSet:{friends:{$each: ['huangbo','zhangyixing']}}})
//WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
// 已经有的时候就不会再添加了
db.grade1.update({_id:3}, {$addToSet:{friends:{$each: ['huangbo','zhangyixing']}}})
//WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 0 })
2
3
4
5
6
- Use with the $push operator to append multiple values to an array .
{ $push: { <field>: { $each: [ <value1>, <value2> ... ] } } }
db.grade1.update({_id:3}, {$push:{friends:{$each: ['huangbo','zhangyixing']}}})
// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
2
在
$addToSet中使用时,若有则忽略,若没有则添加。在$push中使用时,不管有没有都会添加。
# $ne
{field: {$ne: value} } not equal
// 给 name为'Han Meimei' && hobby中不等于'reading' && _id不等于'2'的文档 的hobby 属性 添加一个 'drinking'
db.grade1.update({name: 'Han Meimei', hobby:{$ne:'reading'}, _id: {$ne:'2'}}, {$push: {hobby: 'drinking'}})
// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
2
3
# $set
{ $set: { <field1>: <value1>, ... } }
设置字段的第一层的值(Set Top-Level Fields)
设置嵌套字段的值 (Set Fields in Embedded Documents)
修改指定索引元素
/*
原来的数据:
{_id:3, info:{id: '11'}, friends:['liudehua', 'zhourunfa']}
*/
/*设置字段的第一层的值(Set Top-Level Fields)*/
db.grade1.update({_id:3}, {$set:{"info11":{id:'11'}}})
// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
/*设置嵌套字段的值 (Set Fields in Embedded Documents)*/
db.grade1.update({_id:3}, {$set:{"info.id":'22'}})
// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
/*修改指定索引元素*/
db.grade1.update({_id:3}, {$set:{"friends.1":'zhangmanyu'}})
// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 0 })
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# $unset
{ $unset: { <field1>: "", ... } } 删除指定的键
// 把 {name: 'Tom'} 的文档中的 age 键给删除掉
db.grade1.update({name: 'Tom'}, {$unset:{'age':''}})
// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
/- {
"_id" : ObjectId("5addbfbb163098017a6a72ed"),
"name" : "Tom"
}*/
2
3
4
5
6
7
# 删除文档
- remove方法是用来移除集合中的数据
db.collection.remove(
<query>,
{
justOne: <boolean>
}
)
2
3
4
5
6
query :(可选)删除的文档的条件。
justOne : (可选)如果设为 true 或 1,则只删除匹配到的多个文档中的第一个。默认为 true
/*{justOne:true} 值删除匹配到的第一条文档*/
db.grade1.remove({'name': 'Han Meimei'}, {justOne: true})
// WriteResult({ "nRemoved" : 1 })
/*删除匹配到的所有文档*/
db.grade1.remove({'name': 'Han Meimei'})
// WriteResult({ "nRemoved" : 2 })
db.getCollection('msg_temp_dtl').remove({'_id':ObjectId('603745d8271e000020000c87')},{justOne:false});
2
3
4
5
6
7
8
9
# 查询文档
db.collection_name.find(query, projection)
query - 使用查询操作符指定选择过滤器
projection - 指定配到到的文档中的返回的字段。
/*projection*/
{ field1: <value>, field2: <value> ... }
2
/value:/
1 or true: 在返回的文档中包含这个字段
0 or false:在返回的文档中排除这个字段
_id字段默认一直返回,除非手动将_id字段设置为0或false
findOne()-只返回匹配到的第一条文档
# 查询操作符
# $in
//原始数据():
{ "_id" : 1, "name" : "Tom1", "age" : 9 }
{ "_id" : 2, "name" : "Tom2", "age" : 15 }
{ "_id" : 3, "name" : "Tom3", "age" : 11 }
db.grade1.find({age:{$in:[9,11]}})
// { "_id" : 1, "name" : "Tom1", "age" : 9 }
// { "_id" : 3, "name" : "Tom3", "age" : 11 }
2
3
4
5
6
7
8
# $nin
# $not
db.grade1.find({age:{$not:{$lt:11}}})
//{ "_id" : 2, "name" : "Tom2", "age" : 15 }
//{ "_id" : 3, "name" : "Tom3", "age" : 11 }
2
3
# $gt,$gte$lt,$lte,$ne
# 数组的用法
// 原始数据
{ "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ] }
{ "_id" : 2, "name" : "Tom2", "age" : 15, "friends" : [ "Zhange San", "Li Si" ] }
{ "_id" : 3, "name" : "Tom3", "age" : 11, "friends" : [ "Zhange San", "Lily" ] }
db.grade1.find({"friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ]})
// { "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ] }
db.grade1.find({"friends" : [ "Lily" ]})
// 空
// $all
db.grade1.find({"friends" :{$all: ["Zhang San"]}})
// { "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ] }
// $in
db.grade1.find({"friends" :{$in: ["Zhang San"]}})
{ "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ] }
// $size
db.grade1.find({"friends" :{$size:4}})
//{ "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ] }
// $slice
`db.collection.find( { field: value }, { array: {$slice: count } } );`
> db.grade1.find({"friends" :{$size:4}}, {"friends":{$slice:2}})
//{ "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs" ] }
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# Cursor-Methods
这些方法改变了执行基础查询方式。
包括cursor.forEach()、cursor.map()、cursor.limit()、cursor.size()、cursor.count()等。
// forEach举例
> var result = db.grade1.find({$where: function(){return this.age >= 9}});
> result.forEach(elem => printjson(elem))
/*{
"_id" : 1,
"name" : "Tom1",
"age" : 9,
"friends" : [
"Lily",
"Jobs",
"Lucy",
"Zhang San"
]
}
{
"_id" : 2,
"name" : "Tom2",
"age" : 15,
"friends" : [
"Zhange San",
"Li Si"
]
}
{
"_id" : 3,
"name" : "Tom3",
"age" : 11,
"friends" : [
"Zhange San",
"Lily"
]
}*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 使用_id进行查询
/原始数据
{ "_id" : ObjectId("5ae1b6e3e4366d57f3307239"), "name" : "Tom4" }
> db.grade1.find({_id: '5ae1b6e3e4366d57f3307239'}).count()
// 0
> db.grade1.find({_id:ObjectId('5ae1b6e3e4366d57f3307239')}).count()
// 1
2
3
4
5
6
7
count() 查询结果的条数
# 正则匹配
db.collection.find({key:/value/})
// name是以`T`开头的数据
db.grade1.find({name: /^T/})
/*{ "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ] }
{ "_id" : 2, "name" : "Tom2", "age" : 15, "friends" : [ "Zhange San", "Li Si" ] }
{ "_id" : 3, "name" : "Tom3", "age" : 11, "friends" : [ "Zhange San", "Lily" ] }
{ "_id" : ObjectId("5ae1b6e3e4366d57f3307239"), "name" : "Tom4" }*/
2
3
4
5
6
# and
db.collection_name.find({field1: value1, field2:value2})
# or
db.collection_name.find({ $or: [{key1: value1}, {key2:value2} ] })
# 分页
# limit
读取指定数量的数据记录 语法
db.collectoin_name.find().limit(number)
# skip
跳过指定数量的数据
db.collectoin_name.find().skip(number)
# sort
-通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1为升序排列,而-1是用于降序排列。
db.collectoin_name.find().sort({field:1})
db.collectoin_name.find().sort({field:-1})
# ObjectId构成
之前我们使用MySQL等关系型数据库时,主键都是设置成自增的。但在分布式环境下,这种方法就不可行了,会产生冲突。为此,MongoDB采用了一个称之为ObjectId的类型来做主键。ObjectId是一个12字节的 BSON 类型字符串。按照字节顺序,一次代表:
4字节:UNIX时间戳
3字节:表示运行MongoDB的机器
2字节:表示生成此_id的进程
3字节:由一个随机数开始的计数器生成的值
# mongodb角色
MongoDB 数据库默认角色
- 数据库用户角色:read、readWrite
- 数据库管理角色:dbAdmin、dbOwner、userAdmin
- 集群管理角色:clusterAdmin、clusterManager、clusterMonitor、hostManager
- 备份恢复角色:backup、restore
- 所有数据库角色: readAnyDatabase、readWriteAnyDatabase、userAdminAnyDatabase、dbAdminAnyDatabase
- 超级用户角色:root
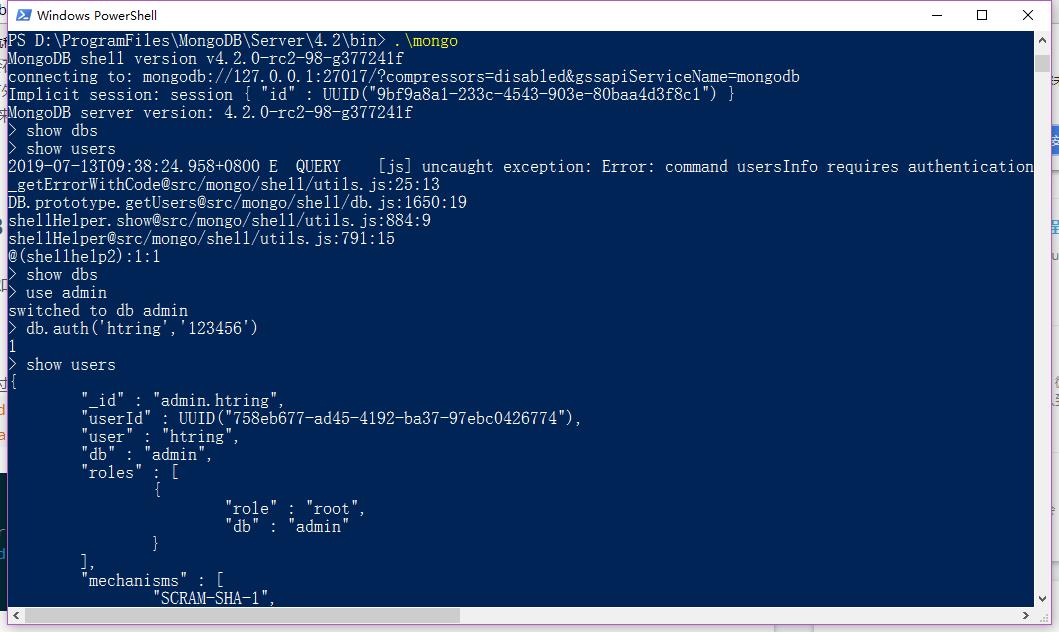
# 本机mongodb
- (dell-home)root(admin)用户:htring/123456
- (dell-company)root(admin)用户:htring/123456
- (dell-home)readWrite(httest)用户:test/test
- (dell-company)readWrite(httest)用户:test/test
登陆验证步骤
use admin
db.auth("htring","123456")
2
返回1则成功验证。